网页开发基础知识
html常用的标签
注释标签、文字标签和段落标签
注释标签
原文
1 | <div class="container"> |
加上注释
1 | <!-- <div class="container"> |
文字标签
格式 <font>……</font>
常用属性
color
1.使用英文单词表示 red black blue green
2.rgb(十六进制,0~9 a~f) 每两位代表一种颜色 red green blue 常用的十六进制颜色: 语法格式:#后面跟上随机6个位数
#ffffff 白色 #000000 黑色 #abcdef 天蓝色 #ff0000 红色
size
size:取值范围1~7之间 如果超出了最大值使用默认最大值7size:取值范围1~7之间 如果超出了最大值使用默认最大值7
举个例子
<font color="red" size="4">宣示—习近平发出新时代改革开放强音</font>
效果如下
宣示—习近平发出新时代改革开放强音
段落标签
格式 <p>……</p>
作用:设置文本的样式(外观) 语法格式:style='属性名:属性值;属性名2:属性值2..'
font-size:修改文字的大小 fonts-size:20px 单位像素 background-color:设置文本的背景颜色
width:设置宽度的属性
1.使用像素 800px 2.使用百分比: 80% height:设置高度的属性
举个例子
<p style="color:white;background: red;width:80%;height:200px;">新浪科技讯 北京时间12月21日早间消息,本周四,苹果宣布约翰·詹南德雷亚(John Giannandrea)进入公司执行团队。不久之前,苹果刚刚任命詹南德雷亚担任AI、机器学习战略高级副总裁。晋升之后,詹南德雷亚直接向苹果CEO库克汇报工作。</p>
效果如下
新浪科技讯 北京时间12月21日早间消息,本周四,苹果宣布约翰·詹南德雷亚(John Giannandrea)进入公司执行团队。不久之前,苹果刚刚任命詹南德雷亚担任AI、机器学习战略高级副总裁。晋升之后,詹南德雷亚直接向苹果CEO库克汇报工作。
和字体相关的其他标签
加粗
1 | <!--加粗--> |
效果
段落
加粗 加粗2
下划线
1 | <!--下划线--> |
效果
下划线
删除线
1 | <!--删除线--> |
效果
删除线 市场价:999现价:99
换行
1 | <!--换行--> |
一举动表明苹果高度重要AI。库克在声明中说:“在苹果,约翰做得很好,
很高兴能看到他加入我们的执行团队。机器学习与AI对于苹果的未来至关重
上标和下标
1 | <p><sup>上标</sup> |
效果
上标 正常显示的文字 下标
斜体
1 | <!--斜体--> |
斜体 斜体2
缩进
1 | <!--缩进--> |
效果
詹南德雷亚在谷歌工作8年,4月份加入苹果。在谷歌工作时,他曾经是搜索、机器智能与研发主管。跳到苹果之后,詹南德雷亚对Siri、Core Ml负责。
标题标签和字符实体
标题标签:<hn></hn> 注意:n的取值范围为1~6的整数
举例
1 | <h1>标题1</h1> |
效果
标题1
标题2
标题3
标题4
标题5
标题6
字符实体
特殊字符
1 | < ---> < |
版权
1 | <!--版权--> |
效果
©北京清华出版社
空格
1 | <!--空格--> |
一名在美中国公民被控窃取商业机密,美方称涉案达18亿
双引号
1 | <!--双引号--> |
"华为回应部分国际银行断交:公司经营稳健,业务运转正常"
和号
1 | <!--和号--> |
11人跨省全链条制贩毒网络团伙&被摧毁,头目是前知名歌手
图像标签和路径
图像标签
格式<img……/>
作用:显示网页上面的图片
常用属性
1.src:图片的路径 2.width:设置图片的宽度 3.height:设置图片的高度 4.alt:图片的替换文本,如果图片资源加载不出来,显示文本 5.title:鼠标悬浮标题
举例
1 | <!--直接设置网页上显示图片,使用图片默认宽高--> |
第六周-面向对象、函数高阶用法
多态
python的多态与java的多态类似。比如一种常见的使用形式就是在函数传参的时候传递的可以是父类和继承该父类的多种子类。然而python比java更灵活
1 | 定义: |
类属性和实例属性
类属性
定义:在类中定义的属性
举个例子
1 | 概述: |
实例属性
定义:定义在init初始化方法中的属性
举个例子,什么是实例属性
1 | #定义一个人类,设置姓名,年龄和地址等属性 |
实例属性和类属性的关系:同名的情况下,实例属性会覆盖类属性
举个例子
1 | #定义一个人类 |
静态方法和类方法
类方法
定义
概述: 类对象所拥有的方法,需要使用到修饰器 @classmethod---->类方法 对于类方法,第一个参数必须是类对象,一般以cls表示作为第一个参数(当然可以用其他的名字,但是不建议修改)
举个例子
1 |
|
静态方法
定义:通过修饰器@staticmethod来进行修饰,不需要传参数
举个例子
1 | 概述: |
总结
类方法:声明方法之前,需要使用到修饰器 @classmethod,里面第一个参数类对象cls,类对象访问的是类属性或者类方法 实例方法:隐含传递的参数是self,对象本身,self访问的可能是实例属性,也有可能是类属性,类方法,静态方法 静态方法:声明方法之前,需要使用到修饰器@staticmethod,不需要加任何参数,访问的是类属性的引用,只能通过类对象调用
__slots__
定义:限制实例属性
语法格式:slots = ('属性1','属性2')
__slots__属性限制添加属性只对当前类的实例对象起作用,对类属性,继承的子类实例对象不起作用的
举个例子
1 | 动态语言:可以在运行的过程中,修改代码 |
@property
私有属性添加getter和setter方法
python中和java类似的是私有属性不能直接修改,需要调用专门的方法才能修改;但python相对于java做出了优化,通过property函数创建一个特性(property),将
getMoney 方法作为获取属性值的方法,setMoney
方法作为设置属性值的方法。这样就可以像访问普通属性一样来访问
Money 类中的 money 属性
举个例子
1 | #定义一个money类,设置一个私有的__money属性 |
使用property取代getter和setter方法
取代set/get------》修饰器-----》@property @property--->属性函数,可以对属性赋值时候做必要的检查,并保证代码的清晰简短 作用: 1.将方法转化为只读 2.重新实现一个属性的设置和读取方法,可做边界判定
举个例子
1 | class Money(object): |
发送邮件
1 | #导入邮件库 |
用列表模拟栈
append模拟入栈
pop模拟出栈
1 | """ |
专门模拟队列的
定义一个队列
1 | import collections |
入队
1 | queue.append(path) |
出队
1 | outDir = queus.popLeft() |
具体事例
1 | """ |
高阶函数
map
定义:根据提供的函数对指定的序列做映射
格式
map(function,iterable) function---》函数,两个参数---》返回值是一个新的列表 iterable---》一个或者多个序列
python2:返回列表 python3:返回的是迭代器
举例
1 | li = [1,2,3,4] |
reduce
定义:reduce()函数会对参数中的元素进行累积
函数将一个数据集合(列表,元组)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
格式:
reduce(function,iterable,[initializer]) function:函数,有两个参数 iterable:可迭代的对象 initializer:可选,初始化参数
举例
1 | from functools import reduce |
filter
定义
filter()函数:用于过滤序列,过滤掉不符合条件的元素,返回由符合条件的元素组成的新列表
格式
filter(function,iterable) function:函数 判断函数 iterable:序列,序列的每一个元素作为参数传递到函数进行判断,返回True,False,最后将返回True的元素存放到一个新的列表中
返回值
Pyhton2返回列表 Python3返回迭代器对象
举个例子
1 | #案例1:筛选指定的元素 |
sorted
定义
sorted()函数对所有的可迭代的对象进行排序的操作 sort: 方法返回的是对已经存在的列表进行操作 sorted:返回值为一个新的list,而不是在原来的基础上进行的操作。
格式
sorted(iterable[, cmp[, key[, reverse]]]) iterable:可迭代的对象 cmp ---》比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。 key ---》主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。 reverse ---》 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
举个例子
1 | lst = [2,0,99,20,100,111] |
第五周作业
exercise1:修改类属性值的两种方式?并写出具体的代码
类属性:
和java相似的是,就是这一类公共的属性,修改这一个其他是这个类(不是同一个对象的)都会变
不同点在于java中类属性是用static修饰的,就是类属性和普通属性之间由严格的界定,而python没有
方法
- 直接通过类名修改类属性的值。
- 通过实例对象修改类属性的值(这种方式会在实例中创建同名的实例属性,并覆盖类属性)。
比如下面
1 | class MyClass: |
exercise2
1 | 2.定义学生类student,在该类中使用构造函数实现对学生信息(姓名、年龄、性别) |
代码
1 | ''' |
exercise3
1 | 3.定义一个学生类。有下面的类属性: |
代码
1 | """ |
exercise4
1 | 4.练习: |
知识点
继承:teacher和student继承自people
通过修改__str__方法来打印信息
代码
1 | """ |
post
论文笔记:Beyond the Prior Forgery Knowledge Mining
Abstract
以前方法存在的问题:
都只是为了捕获特定的伪造线索,比如噪声(noise patterns), 混合边界(blending boundaries)和频率(frequency artifacts),导致容易陷入局部最优,从而降低鲁棒性和泛化能力
创新点
提出CFM框架,原文which can be flexibly assembled with various backbones to boost their generalization and robustness performance,那么是一种模块吗?
CFM框架组成(先把原文放在这,看后面怎么说)
首先构建了一个细粒度的三元组,并通过先验知识不可知的数据增强来抑制特定的伪造痕迹
Specifically, we first build a fine-grained triplet and suppress specific forgery traces through prior knowledge-agnostic data augmentation
随后,我们提出了一个细粒度的关系学习原型,通过实例和局部相似感知损失来挖掘伪造中的关键信息
Subsequently, we propose a fine-grained relation learning prototype to mine critical information in forgeries through instance and local similarity-aware losses
此外,我们设计了一种新颖的渐进式学习控制器来引导模型专注于主要特征组件,使其能够以从粗到精的方式学习关键伪造特征
Moreover, we design a novel progressive learning controller to guide the model to focus on principal feature components, enabling it to learn critical forgery features in a coarse-to-fine manner
INTRODUCTION
研究背景:
以常见的4种伪造手段Deepfakes , Face2Face ,FaceSwap and NeuralTextures为代表的深度伪造技术不断发展,并且越来越多现成的伪造软件被开发被人利用,导致了严重的金融欺诈,假新闻和身份假冒。
早期检测
生物信息,比如眨眼,头部位置不一致和面部扭曲伪影,效果差
基于深度学习的检测,泛化性差
基于深度学习与捕获先验已知的特征,对图像失真的鲁棒性差
目标
抗过拟合的同时挖掘出尽可能多的伪造线索
实现
数据集准备
利用先验知识不可知的数据增强来防止模型陷入局部最优,并驱动模型学习更广义的伪造知识;
学习框架
引入细粒度三元关系学习方案,使模型能够学习更多的固有特征表示
正则化方案
用PLC正则化
目标函数
实例相似度感知损失和局部相似度感知损失来同时学习全局关键特征和局部细微伪影
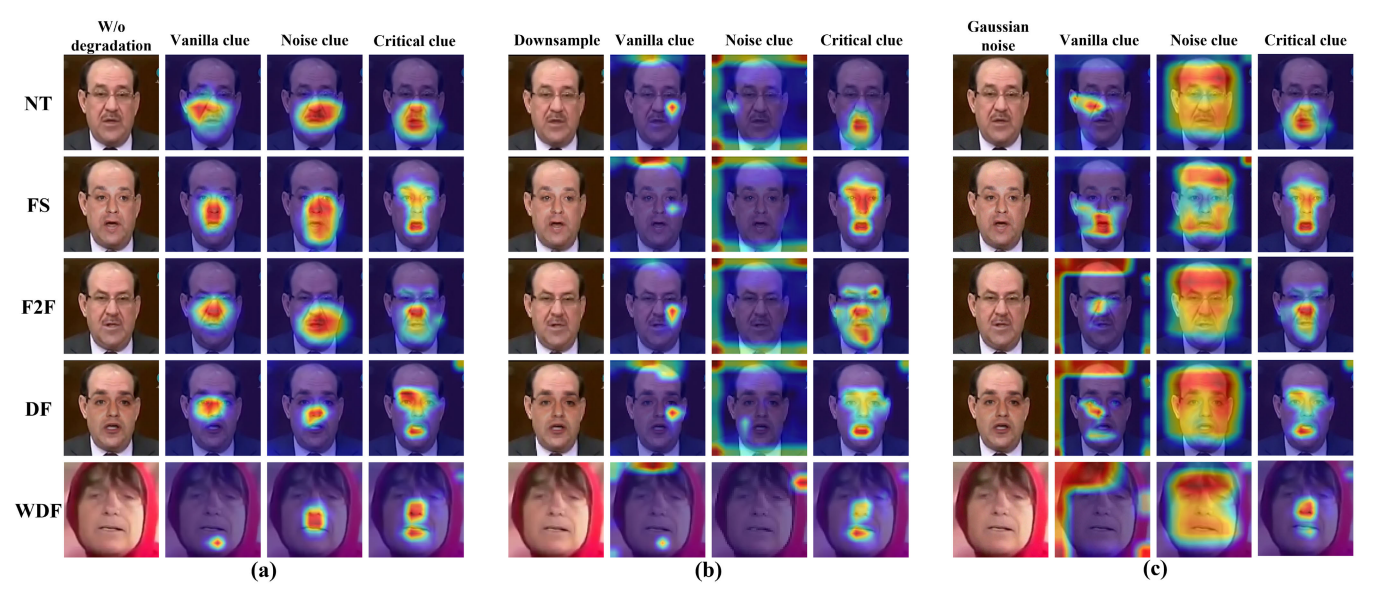
上图每个部分图像第一列是不同形式伪造的图片
提取特征的主干网络都是EfficientNet-B4(可以换成线性transformer试试)
第二列是用普通卷积层提取出的基本伪造特征
第三列是用低频提取出的噪声线索
第四列是用本文提出的CFM框架提取出的关键伪造线索
a部分的图像并没有经过任何变换,b部分的图像经过了下采样,c部分的图像加入了高斯噪声,对比可以看出根据基础线索(估计即使边界)和根据频率线索的检测都受到了干扰
RELATED WORK
A. Prior Knowledge-Based Face Forgery Detection
缺点:抗扰动性差
B. Face Forgery Detection via Representation Learning
Deepfake中的transformer应用
transformer在cv中应用
基础transformer讲解
Position Encoding
前面是没有考虑位置信息的,举个例子
1 | import torch |
输出结果
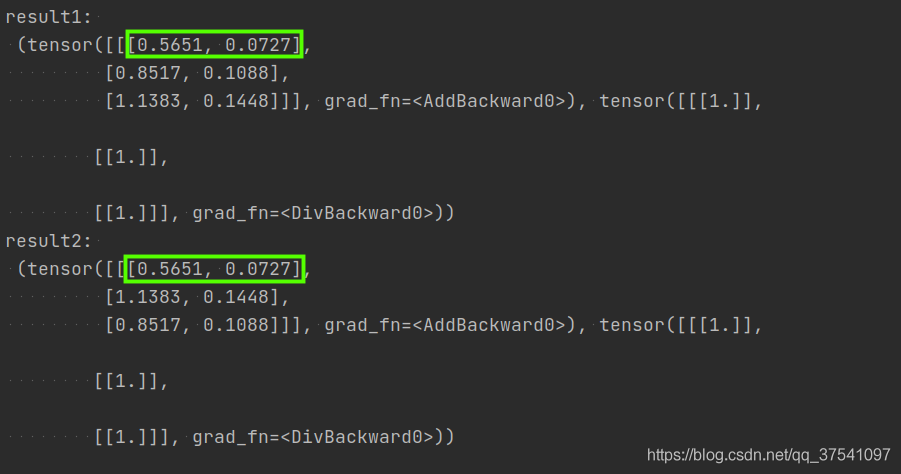
发现对b1没有影响
所以
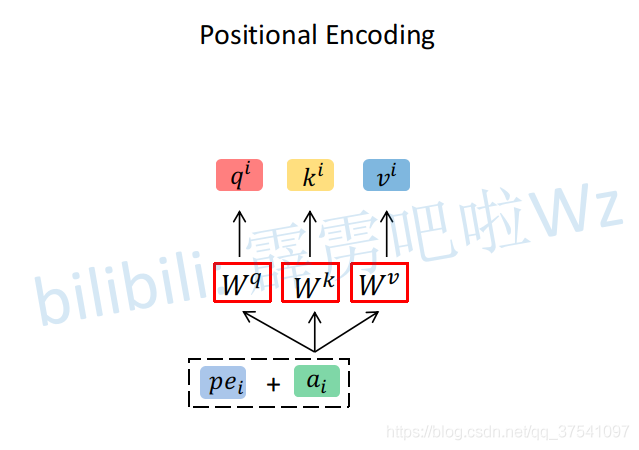
Vision Transformer模型详解
动态规划基础-混境之地5
题目
分析
这题最初的想法用dfs解决,但会超时,分析是因为每次递归计算的值没有利用,所以开一个dp[n][m][k]数组,表示从起点开始,在经过点(x, y),并且在使用喷气背包的次数为t的情况下,能否到达终点
另外要注意地图的边界是从1开始,不是从0开始
代码
1 | import java.util.Scanner; |
DP动态规划入门
基本概念
核心思想
为了解决一个“大”问题,将“大”问题分解成两个“小”问题
举个例子:一次可以走一个台阶或者两个台阶,问走到第n个台阶时,一共有多少种走法?要走到第n级台阶,分成两种情况,一种是从n-1级台阶走一步过来,一种是从n-2级台阶走两步过来
状态
形如dp[i][j] = val的取值,其中i, j为下标,用于描述、确定状态所需的变量,val为状态值
状态转移
状态与状态之间的转移关系,转移方向决定了迭代或递归方向
常见特征:重叠子问题,最优子结构
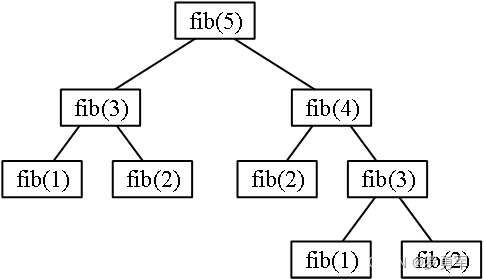
重叠子问题:
斐波那契数为例,用递归计算fib(5),分解为图示的子问题,其中fib(3)计算了2次,其实只算1次就够了
最优子结构
两种编码方法
自顶向下与记忆化
先考虑大问题,再缩小到小问题,递归很直接地体现了这种思路。为避免递归时重复计算子问题,可以在子问题得到解决时,就保存结果,再次需要这个结果时,直接返回保存的结果就行了。这种存储已经解决的子问题的结果的技术称为“记忆化(Memoization)”。 以斐波那契数为例,记忆化代码如下:
1 | int memoize[N]; //保存结果 |
自下而上与制表递推
先解决子问题,再递推到大问题。通常通过填写表格来完成,编码时用若干for循环语句填表。根据表中的结果,逐步计算出大问题的解决方案。
用制表法计算斐波那契数,维护一个一维表dp[],记录自下而上的计算结果,更大的数是前面两个数的和。

1 | const int N = 255; |
分析步骤
确定状态
一般为“到第i个为止,方案数/最小代价/最大价值
确定状态转移方程
根据状态转移方向决定迭代还是递归
确定最终状态
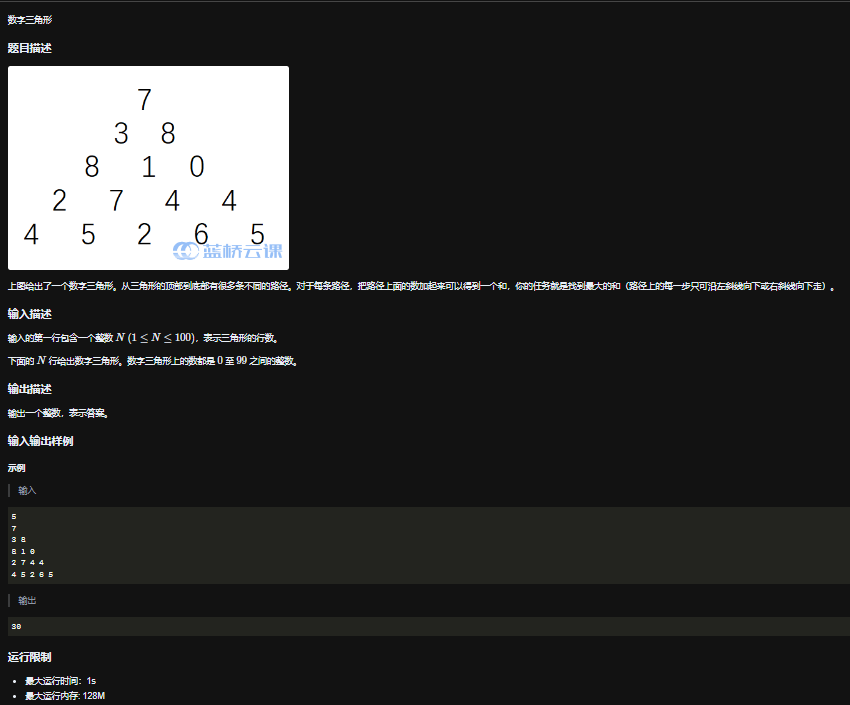
题目一
题干
分析
状态:dp[i][j]表示第i行,第j列的和的最大值
状态迁移方程:方向从底向上,取当前位置的下一层的左边或右边的最大值与当前位置求和,作为当前位置dp值
最终状态:dp[1][1]
代码
1 | import java.util.Scanner; |
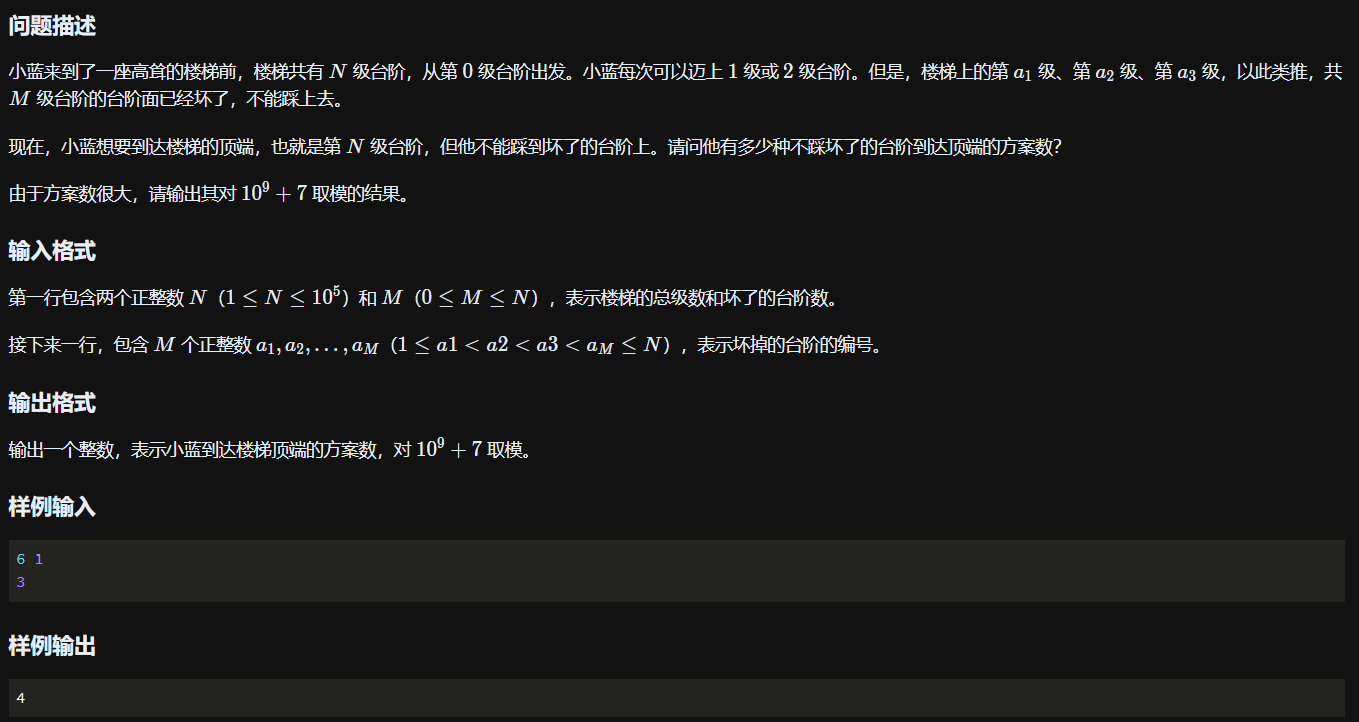
题目二
题干
分析
确定状态:dp[i]表示到第i级台阶有多少种方案
确定状态转移方程:从后往前,dp[i] = dp[i - 1] + dp[i - 2]
确定最终状态:dp[N]
注意,题目中如果告诉你结果比较大,java一般需要开long
代码
1 | import java.util.Scanner; |
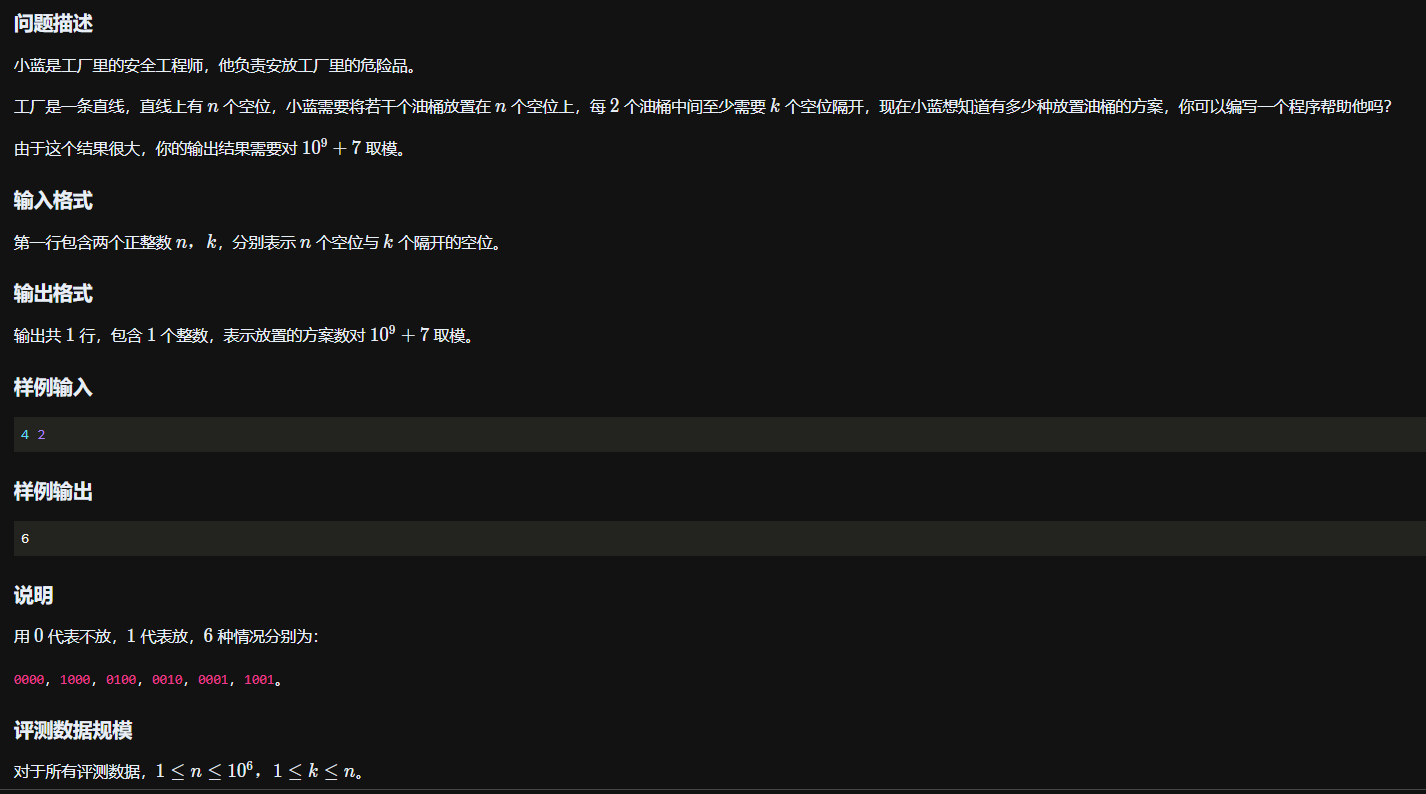
题目三
题干
分析
确定状态

dp[i]:最后一个桶放在位置i的方案总数
状态转移方程
因为dp[i]表示最后一个桶在位置i所具有的方案总数,而要求最近的相邻两个桶之间要相隔k个桶,所以dp[i]等于从最后一个桶在位置1的方案(dp[1])到最后一个桶在位置i - k - 1的方案数(dp[i - k - 1])的和,即\(dp[j] = \sum_{i = 1}^{j - k - 1}dp[i]\)
最终状态
题目要求的是总方案数,由dp数列定义可知不是dp[N],所以要对dp数组求前缀和,prefix[N]才是答案
代码
1 | import java.util.Scanner; |