1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import torch
import torch.nn as nn
m = nn.MultiheadAttention(embed_dim=2, num_heads=1)
t1 = [[[1., 2.],
[2., 3.],
[3., 4.]]]
t2 = [[[1., 2.],
[3., 4.],
[2., 3.]]]
q, k, v = torch.as_tensor(t1), torch.as_tensor(t1), torch.as_tensor(t1)
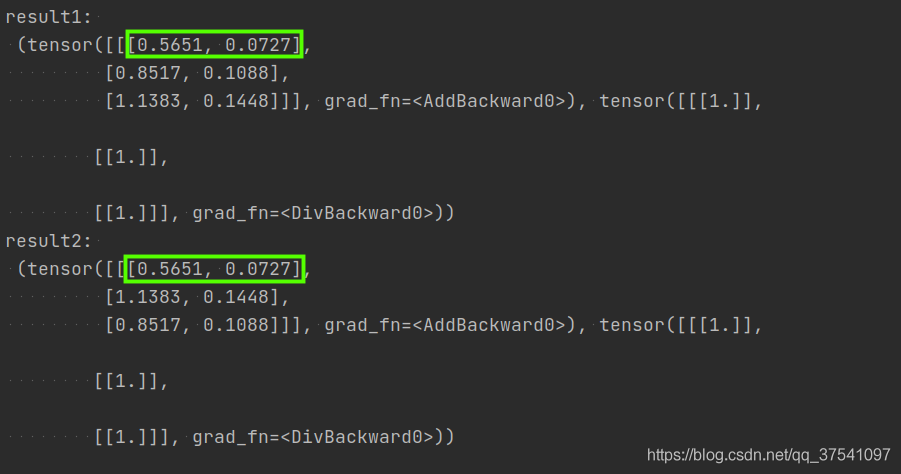
print("result1: \n", m(q, k, v))
q, k, v = torch.as_tensor(t2), torch.as_tensor(t2), torch.as_tensor(t2)
print("result2: \n", m(q, k, v))
|