前期准备工作
配置环境和解释器
配置远程环境
命令行查看所有环境
1 | conda env list |
命令行创建环境
1 | conda create -n env_name python=X.X |
激活指定环境
1 | conda activate env_name |

再用查看所有环境,打*的环境表示是当前激活的环境

配置本地解释器
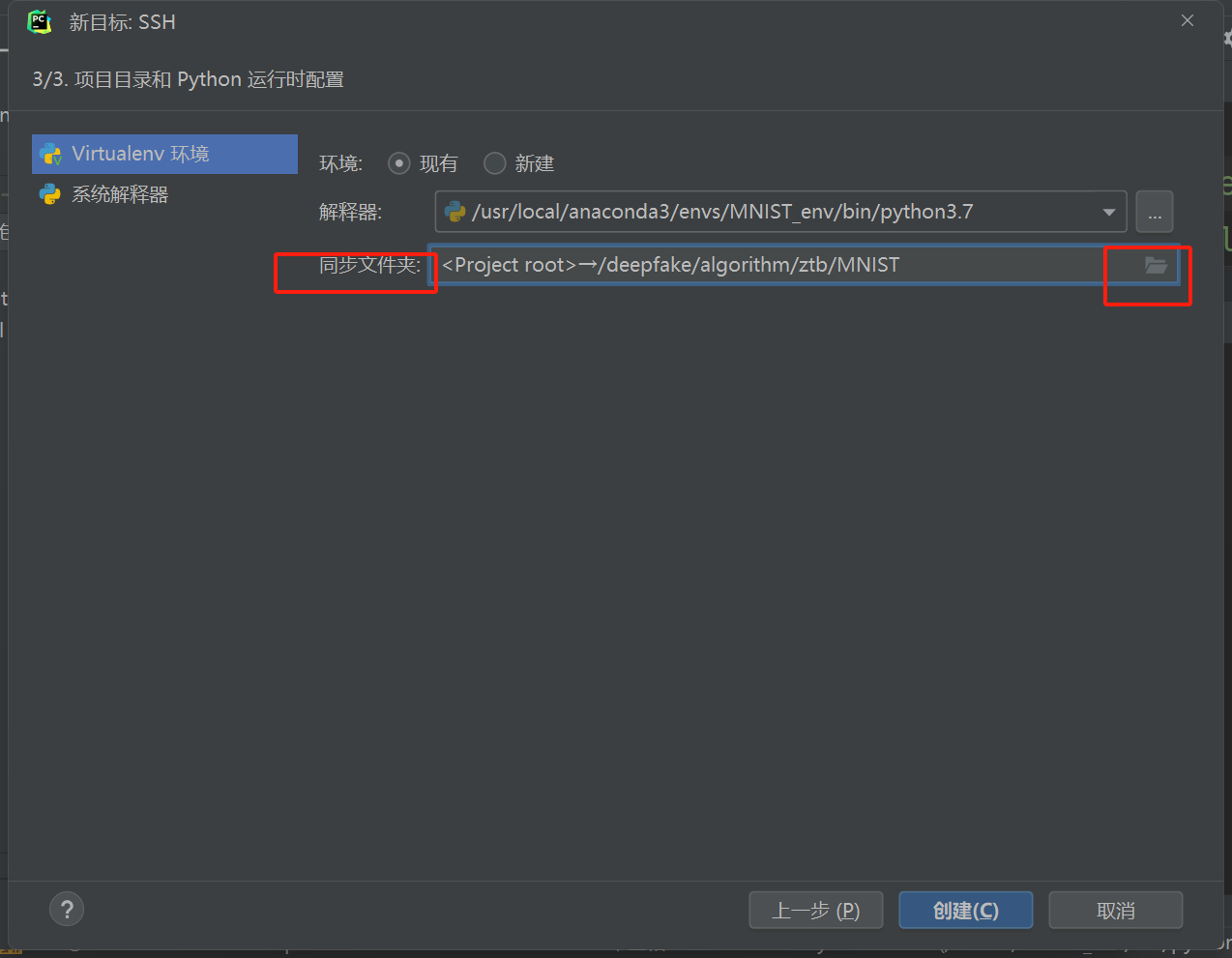
添加SSH解释器
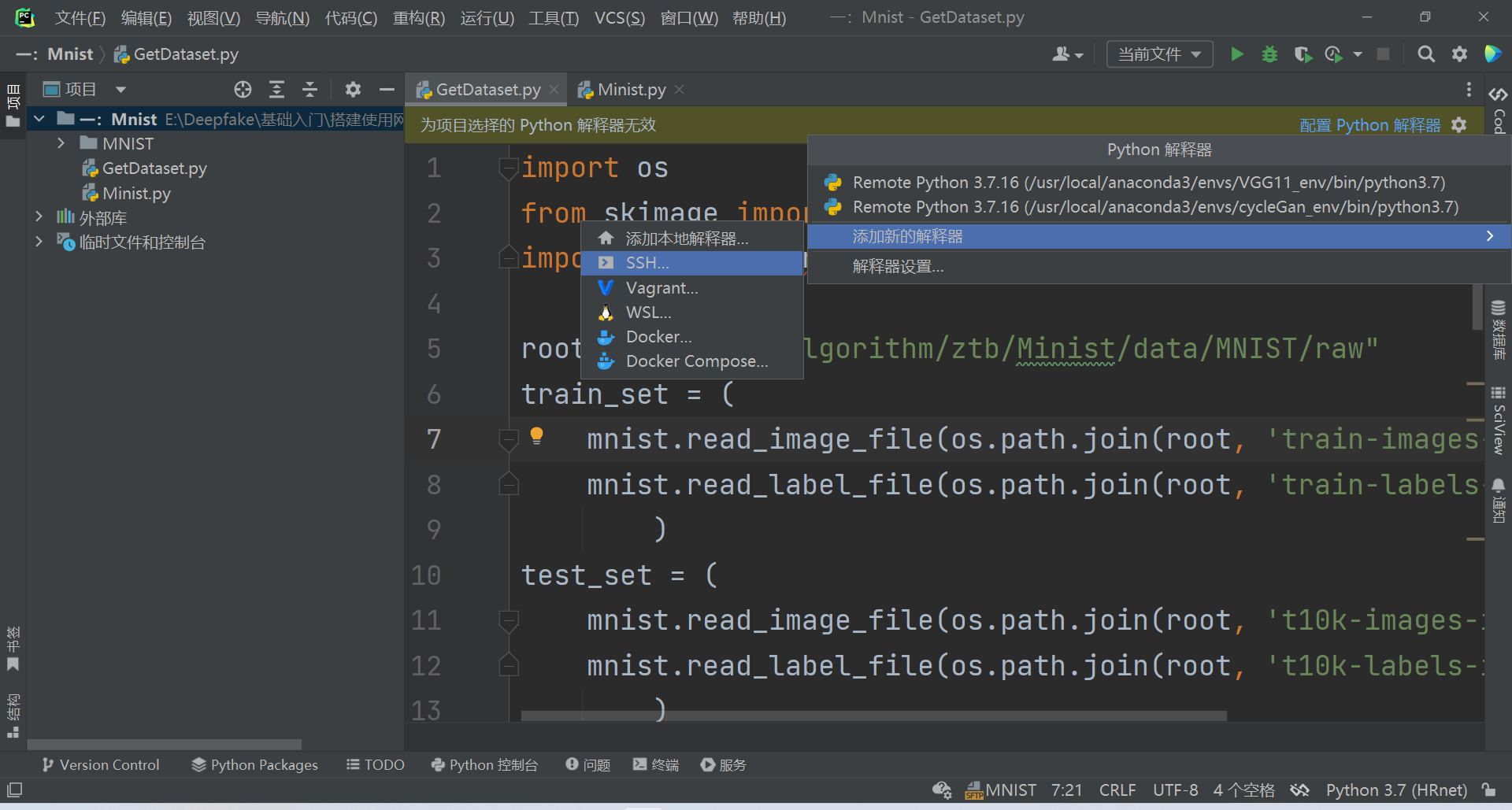
选择现有
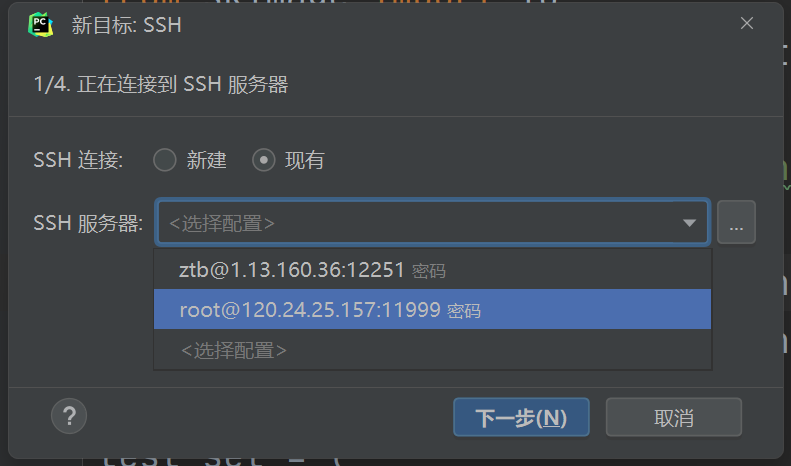
等待内省完毕
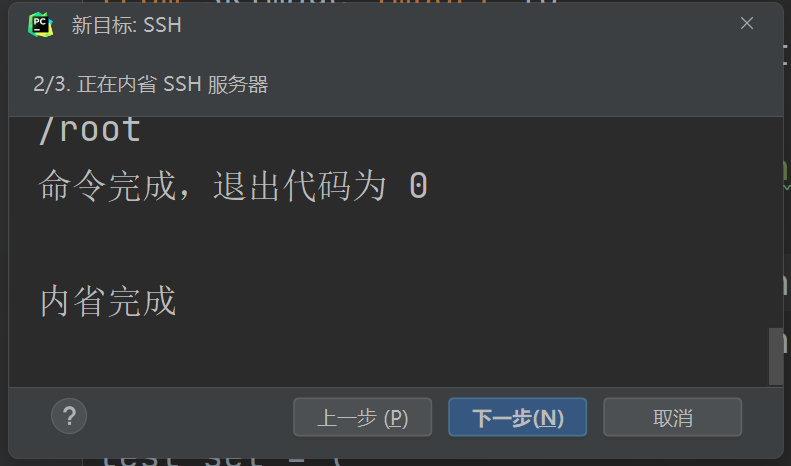
选择现有,找到之前创建的环境位置,后面加上/bin/pythonX.X(最初创建python的版本号)
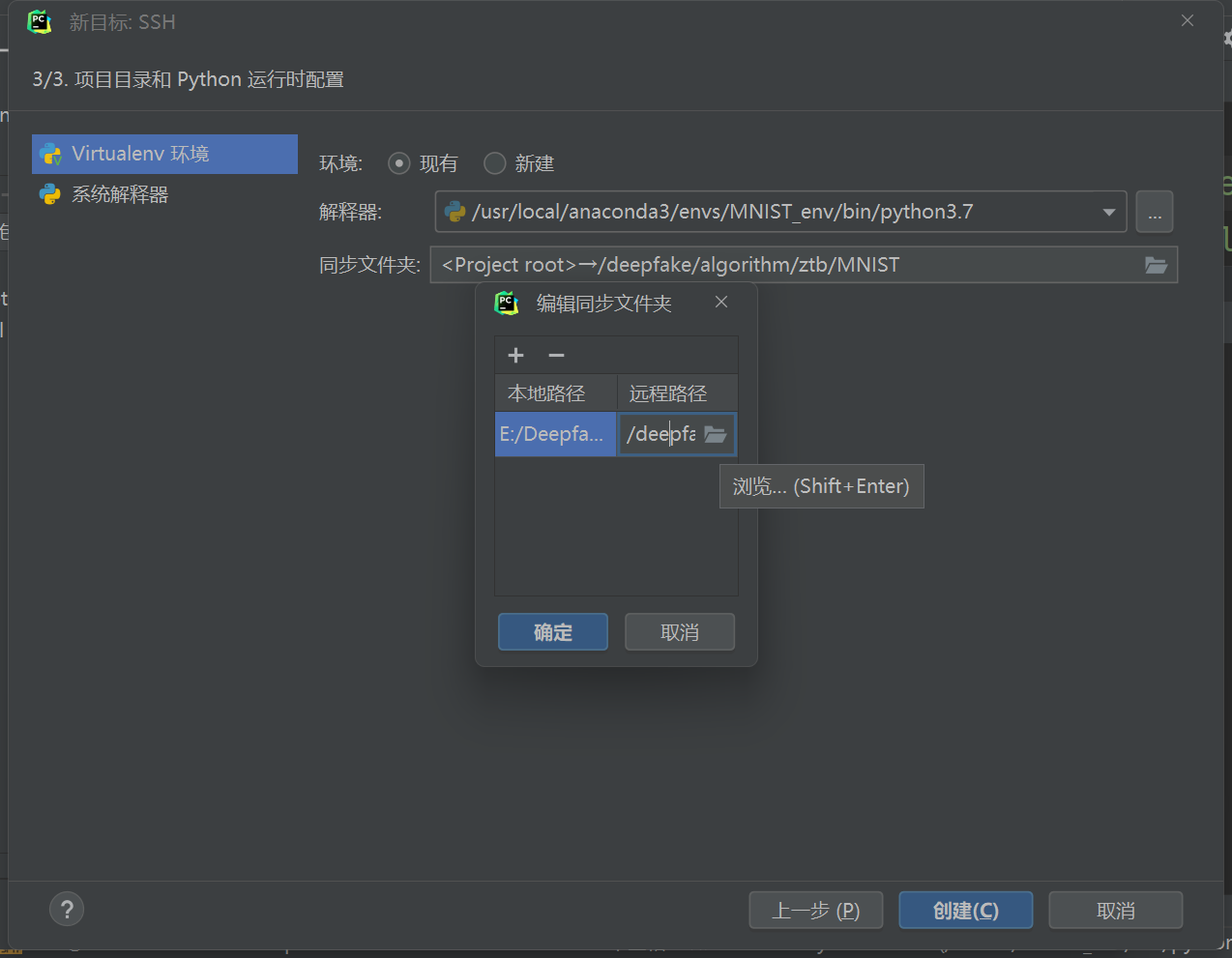
修改同步文件夹的远程文件夹为之前创建project的位置
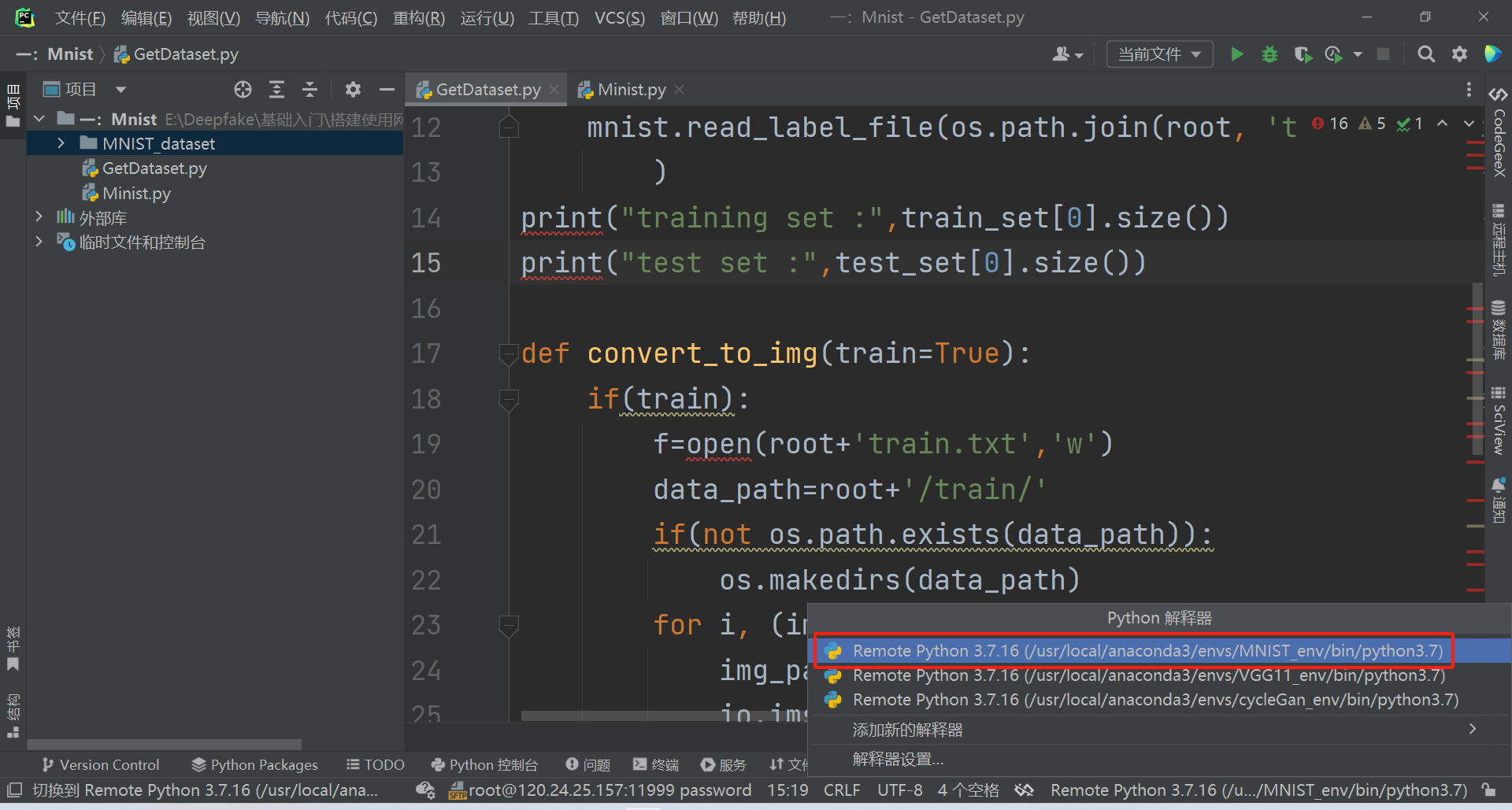
如下所示则配置完成
安装pytorch框架
查看当前cuda版本和python版本,这两个都会决定要下载的pytorch版本
cuda版本查看
1 | nvidia-smi |

到官网下载(下载的版本可以略低与当前CUDA版本),基本上是宁高勿低
查看当前虚拟环境中cuda版本
1 | conda activate cp36 |
项目同步部署到远程服务器
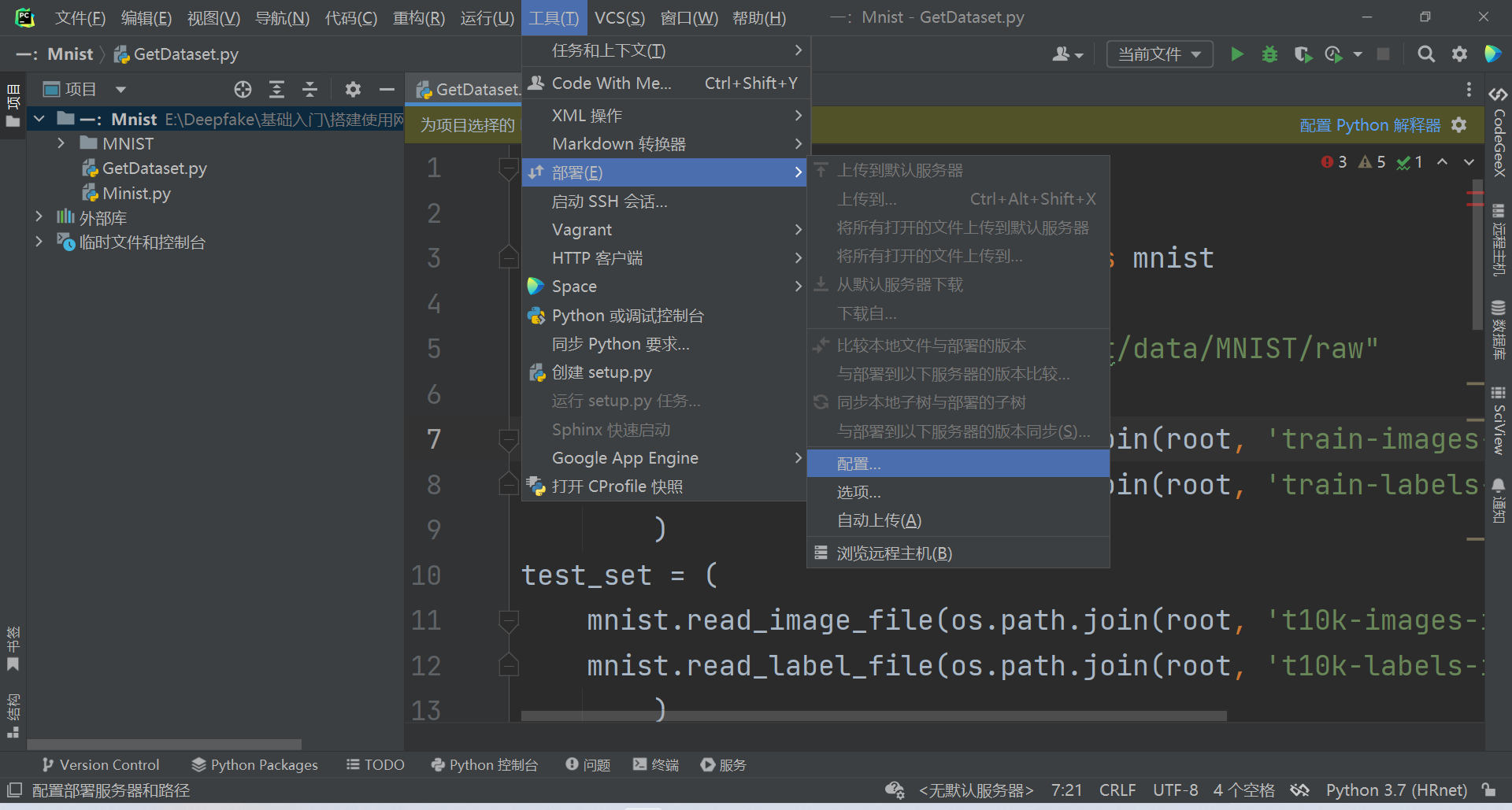
新建选择SFTP
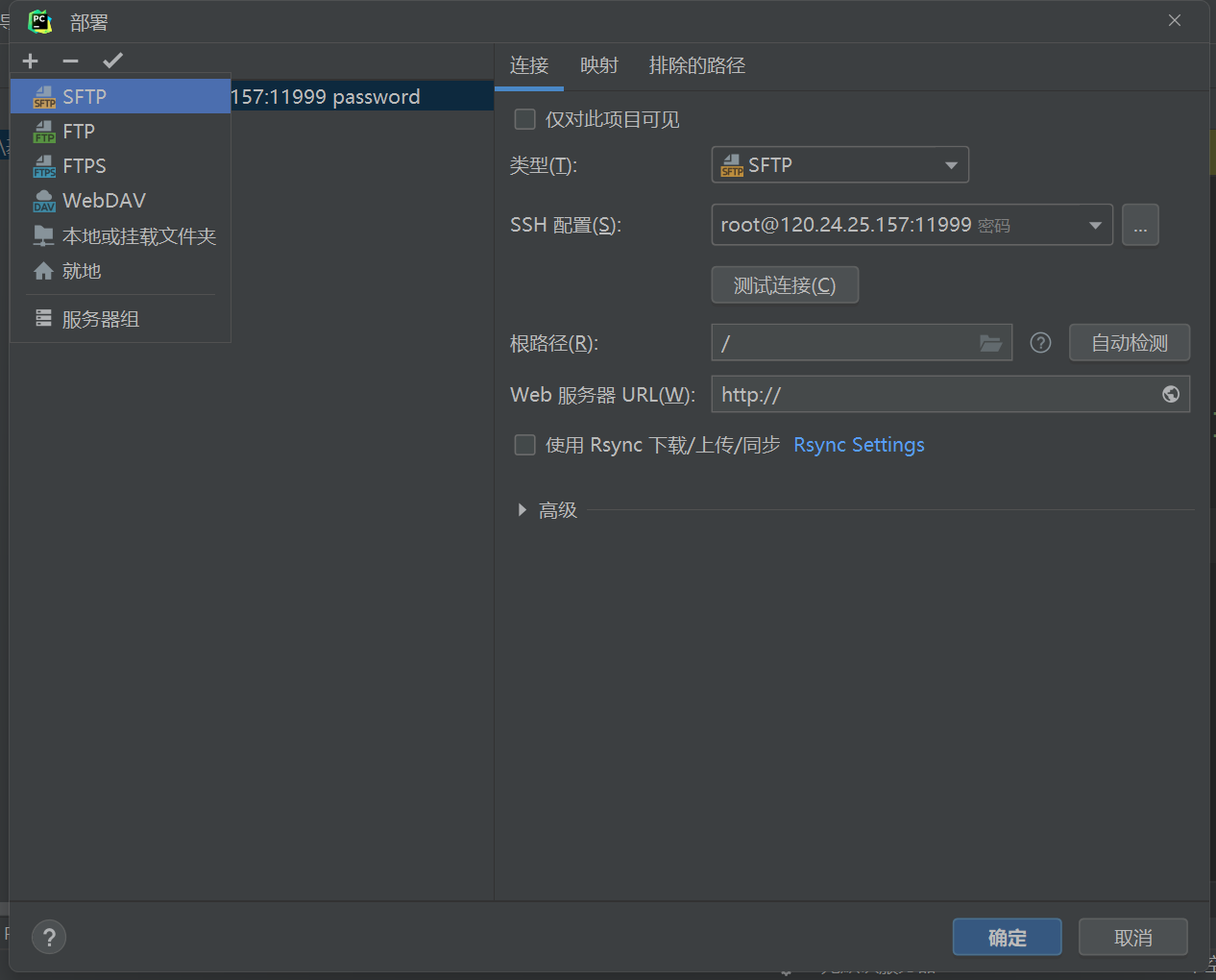
便于区分输入项目名称作为新的服务器部署
配置SSH并测试连接
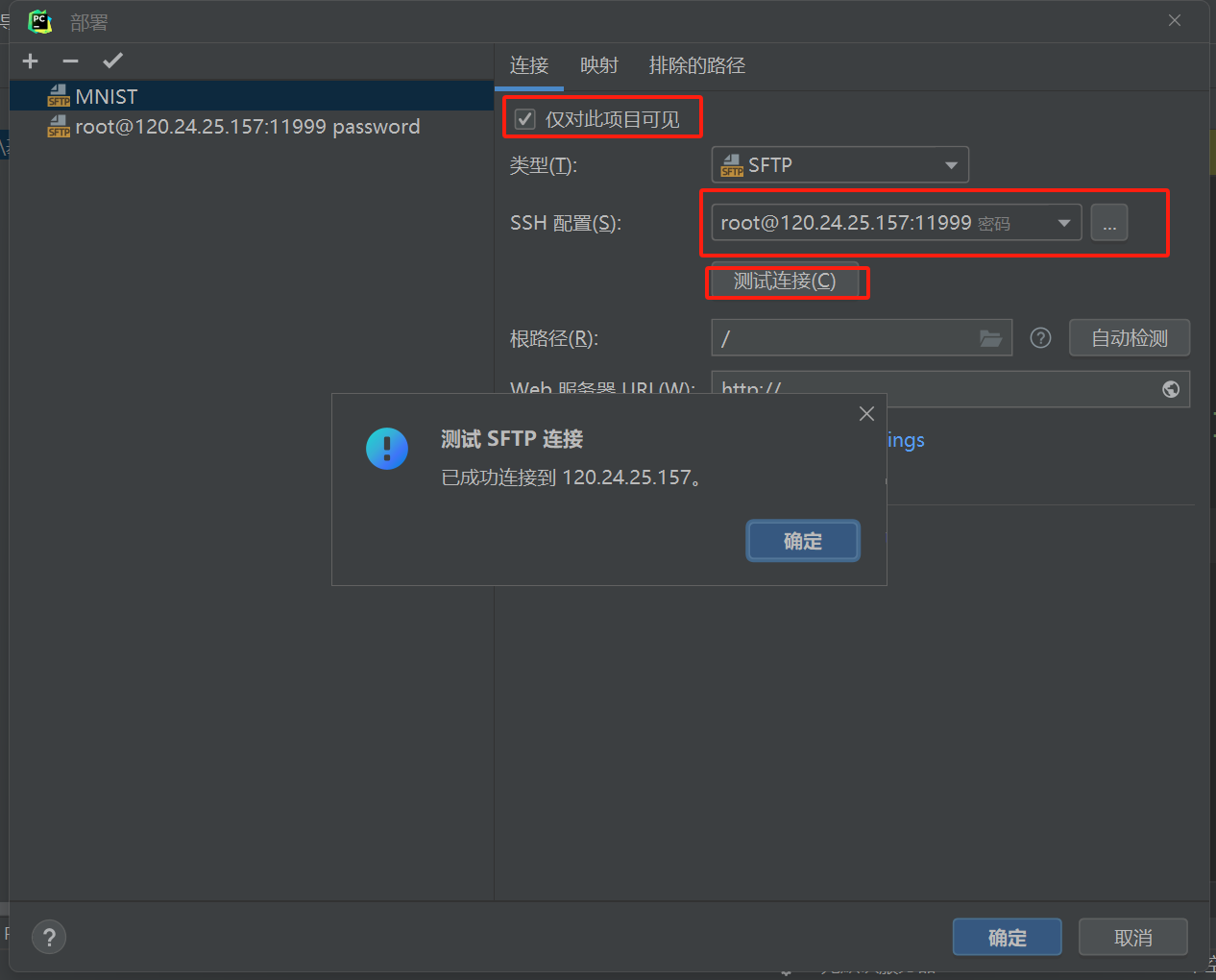
设置项目主文件夹为根路径
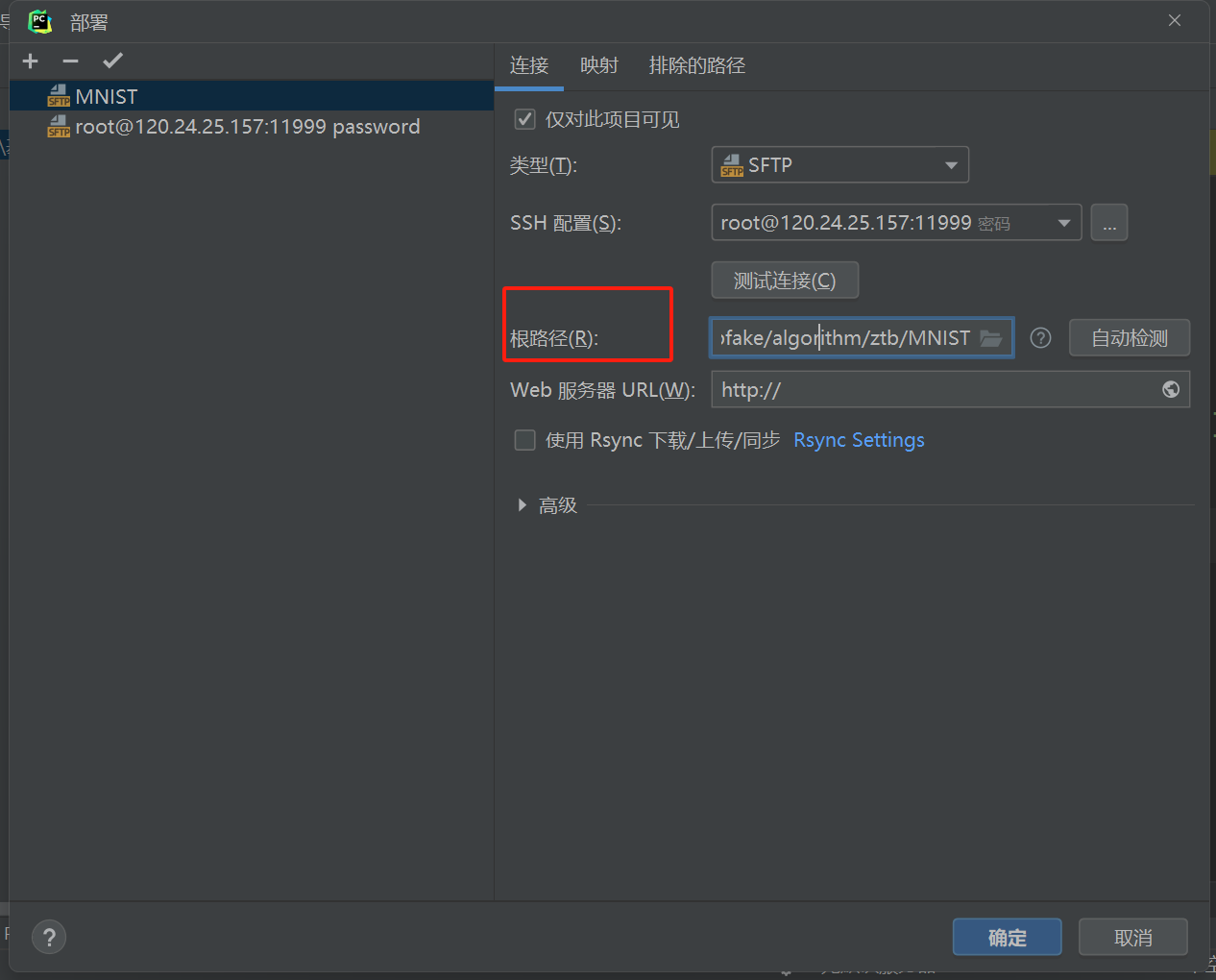
因为之前根路径就是项目主目录,所以部署路径是相对于根目录的相对路径
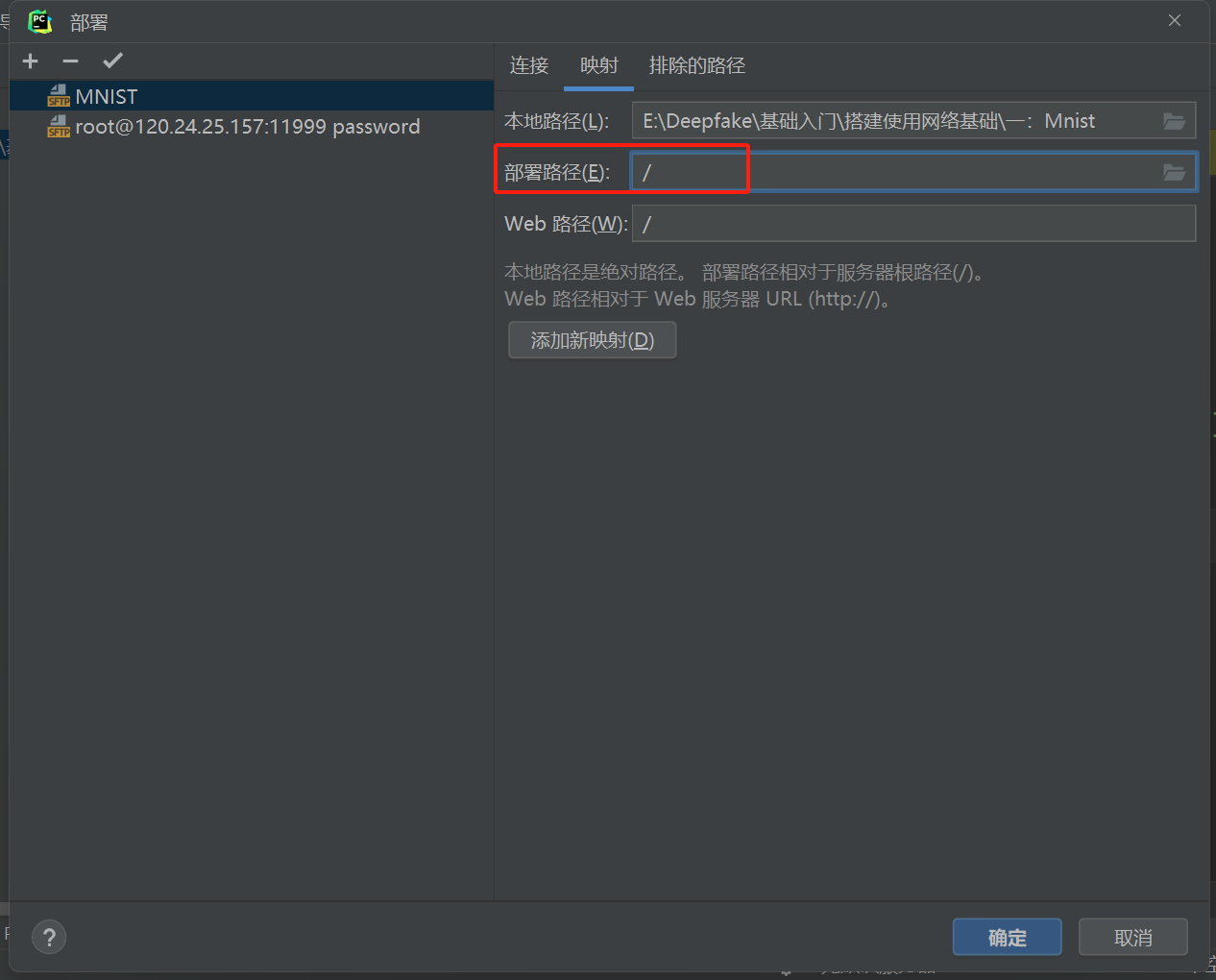
将这个服务器的部署作为默认值
读取数据集
datasets.MNIST(...) 返回一个
torchvision.datasets.MNIST 的实例,而
torch.utils.data.DataLoader
则接收这个数据集实例,并使用指定的参数创建一个 DataLoader
实例
利用torch.util.data.DataLoader创建DataLoader的实例
创建一个dataset的实例(pytorch框架中已经实现了MNIST的set)
数据集要被存储的根目录
下载的是训练集还是测试集
如果数据集尚未下载,是否下载
创建对数据集的操作的transform实列(一般是必备的两条)
将数据集里的图片转化为张量
将数据集里的图片归一化
从数据集里面一次读取的batch_size大小
每次读取后是否打乱原来的数据集
1 | # 建立训练集 |
搭建网络
模板
1 | class ConvNet(nn.Module): |
根据下图搭建

1 | #定义网络 |
定义训练函数
将模型设置为训练模式
利用enumerate遍历dataloader,从中获取训练的批次核(数据,标签)数据-标签对
将数据和标签移动到GPU上
梯度清零
将数据传入模型进行前向传播
计算损失
反向传播
调用优化器更新参数
1 | def train(model, device, train_loader, optimizer, epoch): |
定义测试函数
设置模型为评估模式
初始化测试损失和正确预测的样本数为零
关闭梯度计算
迭代测试集加载器
将输入数据和标签移动到GPU上
使用模型进行前向传播,得到输出
计算交叉熵损失,并将损失累加到test_loss中
利用output和对应label之间计算交叉熵损失,并通过取.item()将张量转换成标量
找到每个样本预测的类别,即具有最大概率的类别。
通过argmax(dim = 1)获得一行的最大值,也就是这一行表示的数据被预测的类别
argmax函数:获得最大值下标
dim=0时获得的是每一列的最大值的下标
dim=1时获得的是每一行的最大值的下标


将预测结果与label比较,其中正确预测的样本数累加到correct中
计算平均测试损失
1 | #定义测试函数 |
完整代码
1 | import torch |