自建数据集完成二分类任务(参考文章 )
1 图片预处理
1 .1 统一图片格式
找到的图片需要首先做相同尺寸的裁剪,归一化 ,否则会因为图片大小不同报错
1 2 RuntimeError: stack expects each tensor to be equal size, but got [3, 667, 406] at entry 0 and [3, 600, 400] at entry 1
pytorch的torchvision.transforms模块提供了许多用于图片变换/增强的函数。
1.1.1 把图片压缩为固定大小
1 transforms.Resize((600,600)),
1.1.2 裁剪保留核心区
因为主体要识别的图像一般在中心位置,所以使用CenterCrop,这里设置为(400,
400)
1 transforms.CenterCrop((400,400)),
1.1.3 处理成统一数据类型
这里统一成torch.float64方便神经网络计算,也可以统一成其他比如uint32等类型
1 transforms.ConvertImageDtype(torch.float64),
1.1.4 归一化进一步缩小图片范围
对于图片来说0~255的范围有点大,并不利于模型梯度计算,我们应该进行归一化。pytorch当中也提供了归一化的函数torchvision.transforms.Normalize(mean,std),
我们可以使用[0.5,0.5,0.5]的mean,std来把数据归一化至[-1,1]
也可以手动计算出所有的图片mean,std来归一化至均值为0,标准差为1的正态分布,
一些深度学习代码常常使用mean=[0.485, 0.456, 0.406]
,std=[0.229, 0.224, 0.225]的归一化数据,这是在ImageNet的几百万张图片数据计算得出的结果
BN等方法也具有很出色的归一化表现,我们也会使用到
Juliuszh:详解深度学习中的Normalization,BN/LN/WN
Algernon:【基础算法】六问透彻理解BN(Batch
Normalization)
我们这里使用简单的[0.5,0.5,0.5]归一化方法,更新cls_dataset,加入transform操作
,作为图片裁剪的预处理。
1 transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
关于transforms的操作大体分为裁剪/翻转和旋转/图像变换/transform自身操作,具体见余霆嵩:PyTorch
学习笔记(三):transforms的二十二个方法 ,这里不进行详细展开。
1.2 数据增强
当数据集较小时,可以通过对已有图片做数据增强,利用之前提到的transforms中的函数
,也可以混合使用来根据已有数据创造新数据
1 2 3 4 self.data_enhancement = transforms.Compose([ transforms.RandomHorizontalFlip(p=1 ), transforms.RandomRotation(30 ) ])
2 创建自制数据集
2.1 以Dataset类接口为模版
构造函数__init__(self)
用于初始化对象。在这个方法中,可以进行一些必要的设置和准备工作,例如加载数据、指定数据集路径等
#### getitem (self, index) Dataset
类的一个必须实现的方法。在这个方法中,需要实现如何从数据集中获取数据和标签,并以返回数据样本(feature)对应的标签(label)。
#### len (self) Dataset
类的一个必须实现的方法。它用于返回数据集中样本的总数。
1 2 3 4 5 6 7 8 9 10 from torch.util.data import Datasetclass cls_dataset (Dataset ): def __init__ (self ) -> None : 。 def __getitem__ (self, index ): def __len__ (self ):
2.2 创建set
2.2.1定义两个空列表data_list和target_list
2.2.2遍历文件夹
2.2.3读取图片对象,对每一个图片对象预处理后,分别将图片对象和对应的标签加入data_list和target_list中
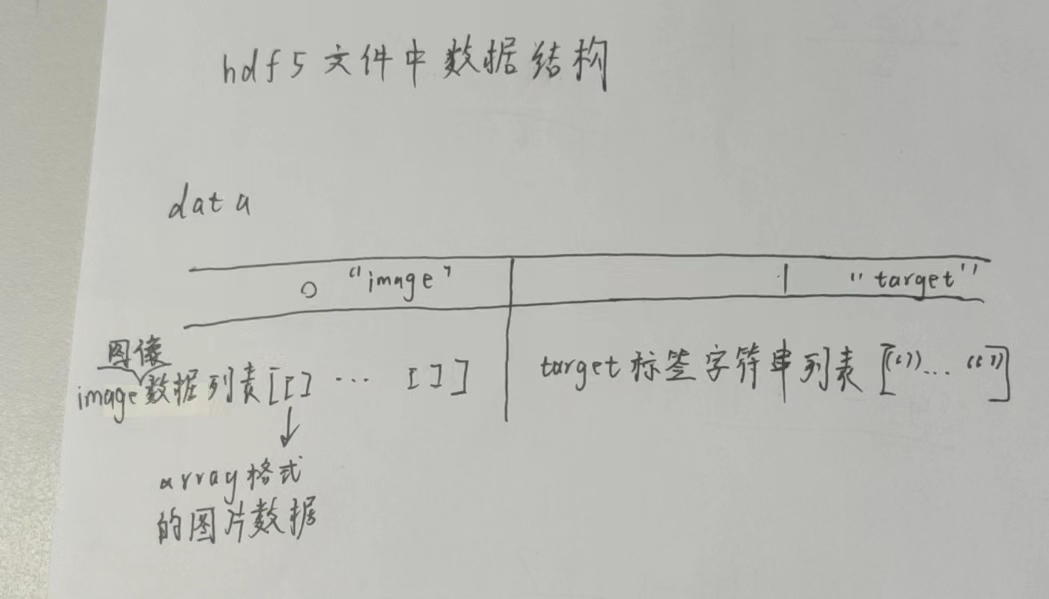
2.2.4将data_list和target_list加入h5dfile中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 import numpy as npimport torchfrom torch.utils.data import Datasetfrom torchvision import transformsimport osimport h5pyfrom torchvision.io import read_imagefrom tqdm import tqdmclass bird_flower_dataset (Dataset ): def __init__ (self, file_path, train_dataset_path, test_dataset_path ): super ().__init__() self.labels = ['bird' , 'flower' ] self.file_path = file_path self.train_dataset_path = train_dataset_path self.test_dataset_path = test_dataset_path if not os.path.exists(file_path): self._create_h5_file(self) def __getitem__ (self, index ): with h5py.File(self.file_path, 'r' ) as f: if f['label' ][index].decode() == "bird" : label = torch.tensor(0 ) else : label = torch.tensor(1 ) return f['image' ][index], label def __len__ (self ): with h5py.File(self.file_path, 'r' ) as f: return len (f['label' ]) @staticmethod def _create_h5_file (self ): with h5py.File(self.file_path, 'w' ) as f: transform = transforms.Compose([ transforms.Resize((600 , 600 )), transforms.CenterCrop((400 , 400 )), transforms.ConvertImageDtype(torch.float64), transforms.Normalize([0.5 , 0.5 , 0.5 ], [0.5 , 0.5 , 0.5 ]) ]) img_list = [] label_list = [] dataset_kind = self.file_path.split('.' )[0 ] if dataset_kind == 'train' : dataset_path = self.train_dataset_path else : dataset_path = self.test_dataset_path ''' 文件夹组成 | —— train | | —— flower | | | —— 图片1 | | —— bird | | —— | —— 图片2 | —— test | | —— flower | | —— bird ''' for directory, _, images in tqdm(os.walk(dataset_path)): label = directory.split('/' )[-1 ] for img in images: img = read_image(os.path.join(directory, img)) img = transform(img) img = np.array(img).astype(np.float64) img_list.append(img) label_list.append(label.encode()) f.create_dataset("image" , data=img_list) f.create_dataset("label" , data=label_list)
2.3 创建loader
1 2 3 4 5 6 7 8 9 10 11 12 train_loader = DataLoader( bird_flower_dataset("train.hdf5" , train_set_path, test_set_path), batch_size=4 , shuffle=True , ) test_loader = DataLoader( bird_flower_dataset("test.hdf5" , train_set_path, test_set_path), batch_size=4 , shuffle=True )
3 搭建网络
网络结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from torch import nnimport torch.nn.functional as Fclass conv_net (nn.Module): def __init__ (self ): self.conv1 = nn.Conv2d(in_channels=3 , out_channels=16 , kernel_size=5 ) self.maxpool = nn.MaxPool2d(kernel_size=2 , stride=2 ) self.conv2 = nn.Conv2d(in_channels=16 , out_channels=64 , kernel_size=3 ) self.fc1 = nn.Linear(in_features=64 * 98 * 98 , out_features=500 ) self.fc2 = nn.Linear(in_features=500 , out_features=2 ) self.flatten = nn.Flatten() def __forward__ (self, x ): output = self.conv1(x) output = F.relu(output) output = self.maxpool(output) output = self.conv2(output) output = F.relu(output) output = self.maxpool(output) output = self.flatten(output) output = self.fc1(output) output = F.relu(output) output = self.fc2(output) return output
4 训练与测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def train (model, device, train_loader, optimizer, epoch ): model.train() for batch_idx, (data, label) in enumerate (train_loader): data, label = data.type (torch.FloatTensor).to(DEVICE), label.to(DEVICE) optimizer.zero_grad() output = model(data) loss = F.cross_entropy(output, label) loss.backward() optimizer.step() print (f'Train Epoch: {epoch} [{batch_idx * len (data)} /{len (train_loader.dataset)} ({100. * batch_idx / len (train_loader):.0 f} %)]\tLoss: {loss.item():.6 f} ' ) def test (model, device, test_loader ): model.eval () test_loss = 0 correct = 0 criterion = nn.CrossEntropyLoss() with torch.no_grad(): for data, label in test_loader: data, label = data.type (torch.FloatTensor).to(device), label.to(device) output = model(data) test_loss += criterion(output, label).item() pred = output.argmax(dim=1 ) correct += pred.eq(label).sum ().item() test_loss /= len (test_loader.dataset) print (f"\nTest set: Average loss: {test_loss :.4 f} , Accuracy: {correct} / {len (test_loader.dataset)} ({100. * correct / len (test_loader.dataset) :.2 f} %)\n" )
5 保存模型
训练好后保存模型
1 2 3 model = ConvNet().to(DEVICE) model.load_state_dict(torch.load(f'model_weights/best_model.pth' ))
使用之前保存好的模型
1 2 3 4 5 test_image = load_and_preprocess_image(test_image_path) prediction = predict_single_image(model, test_image, DEVICE)