深度卷积神经网络AlexNet

组成
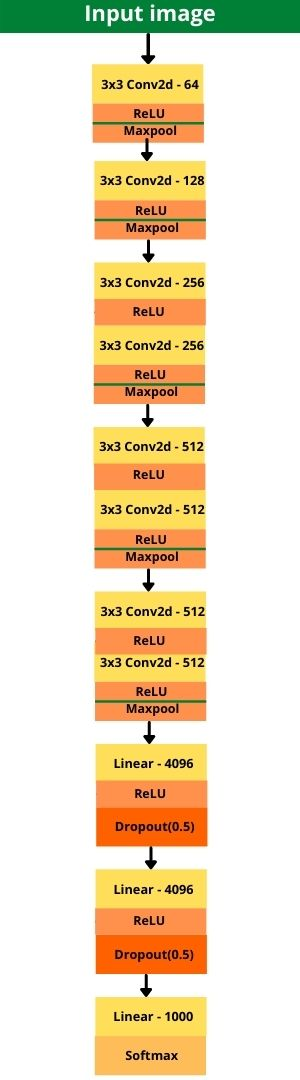
- AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet使用ReLU而不是sigmoid作为其激活函数
- 通过暂退法控制全连接层的模型复杂度
VGG网络
组成
经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。
VGG网络可以分为两部分:
第一部分主要由卷积层和汇聚层组成
第二部分由全连接层组成

VGG神经网络连接
的几个VGG块(在vgg_block函数中定义)。其中有超参数变量conv_arch。该变量指定了每个VGG块里卷积层个数和输出通道数。
如下是一种VGG11网络
运用:在前向传播的过程中从之前层的拼接变成块的拼接
就是常常用如下写法将卷积层,激活函数,池化层放到一个块中,全连接层,激活函数,Dropout函数放到另一个层,
1 | import torch |
网络中的网络NiN
设计思想
1.NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层
2.将空间维度中的每个像素视为单个样本,将通道维度视为不同特征(feature)。
组成

卷积块NiN设计
NiN块以一个普通卷积层开始,后面是两个1×1的卷积层。这两个1×1卷积层充当带有ReLU激活函数的逐像素全连接层。 第一层的卷积窗口形状通常由用户设置。 随后的卷积窗口形状固定为1×1。
上面这样的块设计三个,每个块的第一个卷积层窗口形状为11×11、5×5和3×3
每个NiN块后有一个最大汇聚层,汇聚窗口形状为3×3,步幅为2。
取消全连接层的替代设计
NiN完全取消了全连接层,使用一个NiN块,其输出通道数等于标签类别的数量
通过一个全局平均汇聚层(global average pooling layer),生成一个对数几率 (logits)
1 | def nin_block(in_channels, out_channels, kernel_size, strides, padding): |
含并行连结的网络(GoogLeNet)
吸收了NiN中串联网络的思想,并在此基础上做了改进
解决了什么样大小的卷积核最合适的问题
组成

卷积块Inception块

由四条并行路径组成
前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息,其中1×1卷积层直接接到通道合并层,3×3和5×5的卷积层是先在输入上执行1×1卷积,以减少通道数,从而降低模型的复杂性,然后再分别接上,最后接到合并层
第四条路径使用3×3最大汇聚层,然后使用1×1卷积层来改变通道数
这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出
注:通常调整的超参数是每层输出通道数。
1 | import torch |
其他块
b1

1 | b1 = nn.Sequential( |
b2
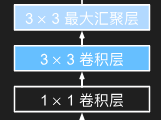
1 | b2 = nn.Sequential( |
b3
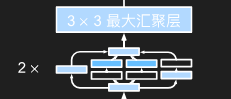
1 | b3 = nn.Sequential( |
b4
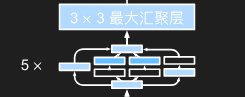
1 | b4 = nn.Sequential( |
b5
1 |
|
残差网络(ResNet)
## 组成
残差块

基本定义:
假设我们的原始输入为x,而希望学出的理想映射为f(x),上图左图虚线框中的部分需要直接拟合出该映射f(x),而右图虚线框中的部分则需要拟合出残差映射f(x) - x
在残差块中,输入可通过跨层数据线路更快地向前传播
组成
基本结构
残差块里首先有2个有相同输出通道数的3×3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数,然后通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前
要求2个卷积层的输出与输入形状一样,从而使它们可以相加
改变通道数
通过引入一个额外的1×1卷积层来将输入变换成需要的形状(另一条正常计算的路已经改变通道数了)后再做相加运算
代码实现
1 | import torch |
生成两种类型的网络:
一种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。
另一种是当use_1x1conv=True时,添加通过1×1卷积调整通道和分辨率。

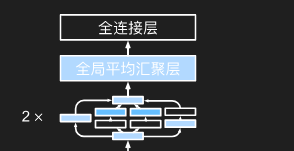
其他块(以ResNet-18为例)

b1
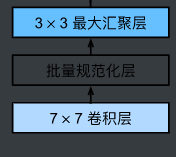
前两层在输出通道数为64、步幅为2的7×7卷积层后接批量规范化层,再接步幅为2的3×3的最大汇聚层
1 | self.b1 = nn.Sequential( |
b2, b3, b4, b5
使用4个由残差块组成的模块,
每个模块使用若干个残差块构成(下面举的例子是2个)。
第一个模块的通道数同输入通道数一致。 因为之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
1 | def resnet_block(input_channels, num_channels, num_residuals, first_block=False): |
在ResNet中加入全局平均汇聚层,以及全连接层输出。
1 | net = nn.Sequential(b1, b2, b3, b4, b5, |
完整残差网络实现
1 | import torch |