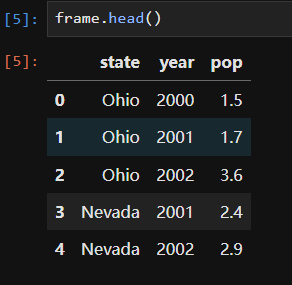
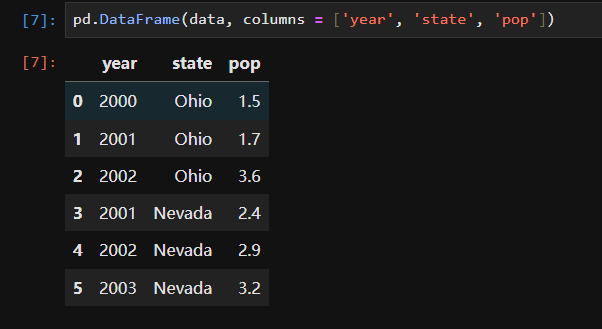
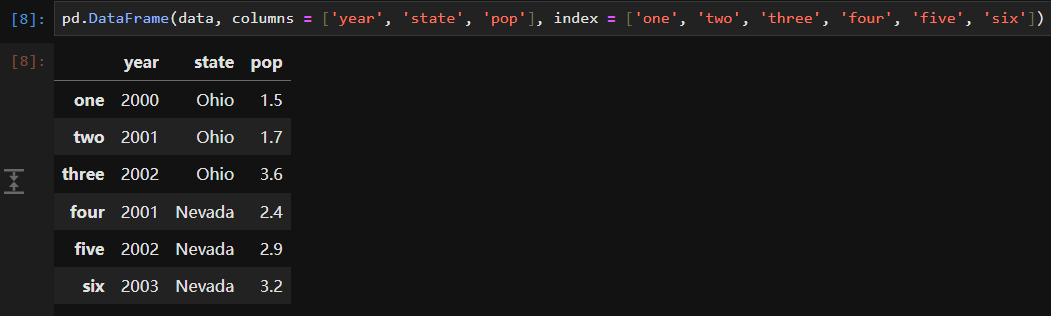
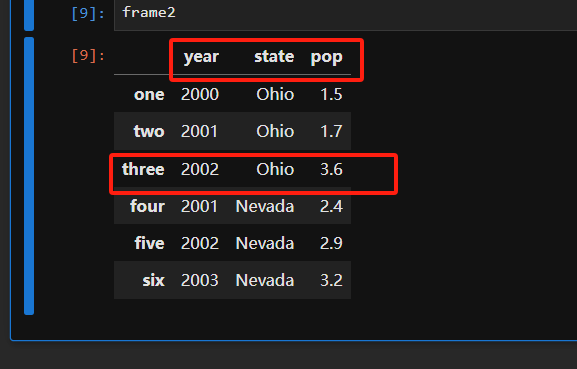
In [29]: states = ['California', 'Ohio', 'Oregon', 'Texas']
In [30]: obj4 = pd.Series(sdata, index=states)
In [31]: obj4 Out[31]: California NaN Ohio 35000.0 Oregon 16000.0 Texas 71000.0 dtype: float64
在这个例子中,sdata中跟states索引相匹配的那3个值会被找出来并放到相应的位置上,但由于"California"所对应的sdata值找不到,所以其结果就为NaN(即“非数字”(not
a
number),在pandas中,它用于表示缺失或NA值)。因为‘Utah’不在states中,它被从结果中除去。
isnull和notnull函数可用于检测缺失数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
In [32]: pd.isnull(obj4) Out[32]: California True Ohio False Oregon False Texas False dtype: bool
In [33]: pd.notnull(obj4) Out[33]: California False Ohio True Oregon True Texas True dtype: bool
Series也有类似的实例方法:
1 2 3 4 5 6 7
In [34]: obj4.isnull() Out[34]: California True Ohio False Oregon False Texas False dtype: bool
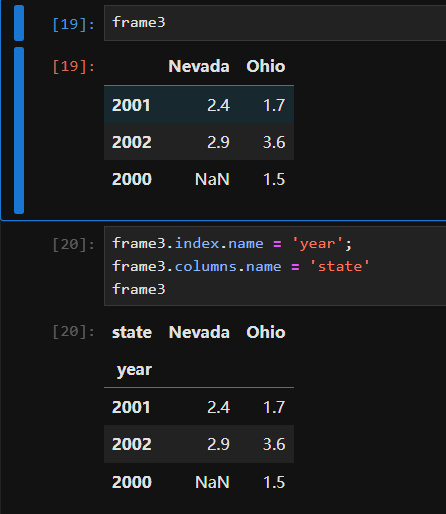
name属性
1 2 3 4 5 6 7 8 9 10 11 12
In [38]: obj4.name = 'population'
In [39]: obj4.index.name = 'state'
In [40]: obj4 Out[40]: state California NaN Ohio 35000.0 Oregon 16000.0 Texas 71000.0 Name: population, dtype: float64
修改索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
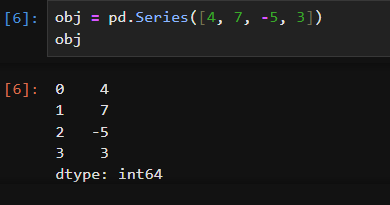
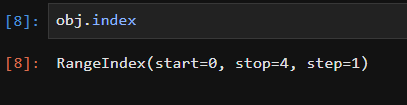
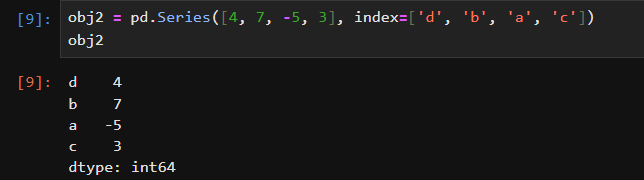
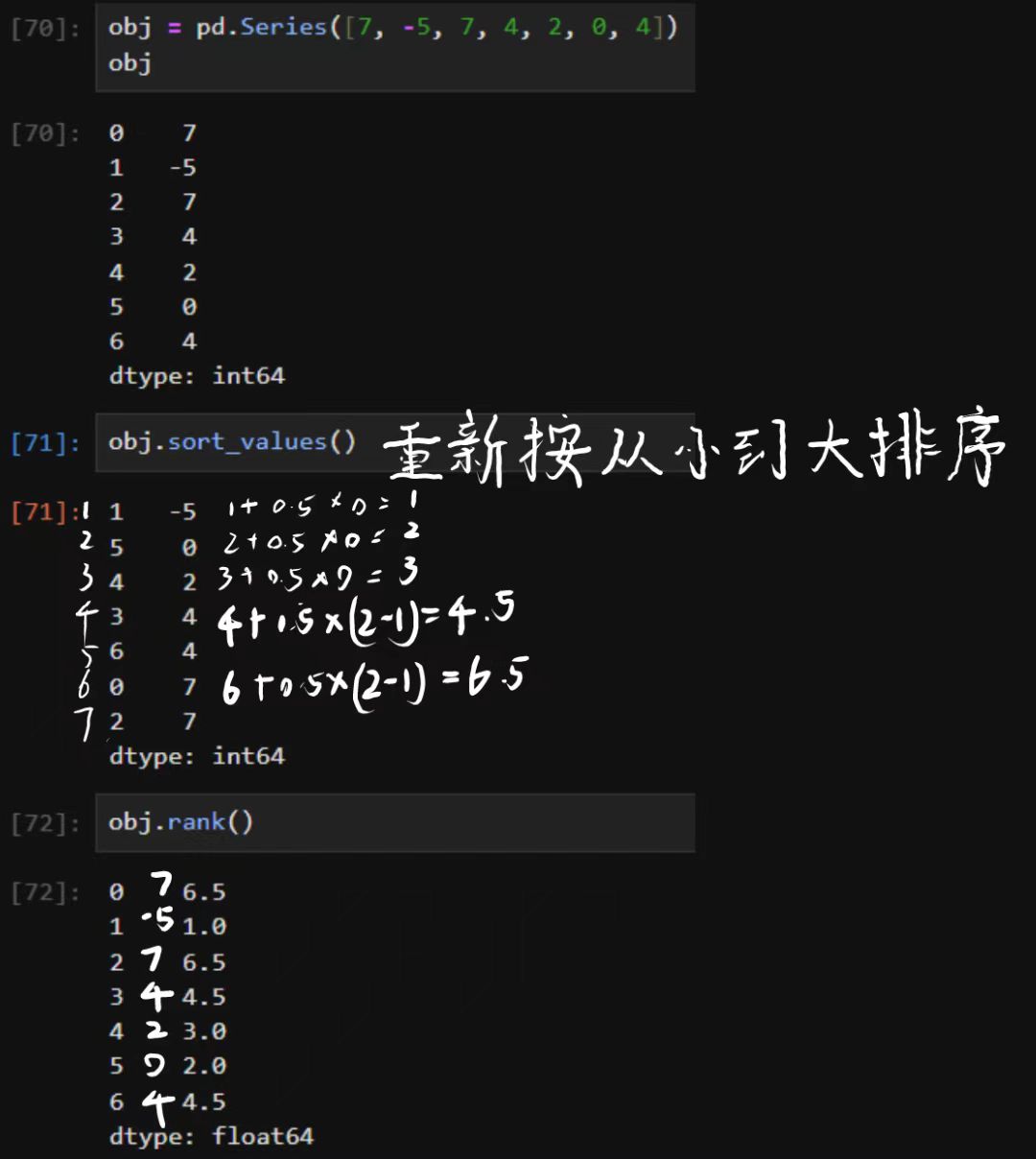
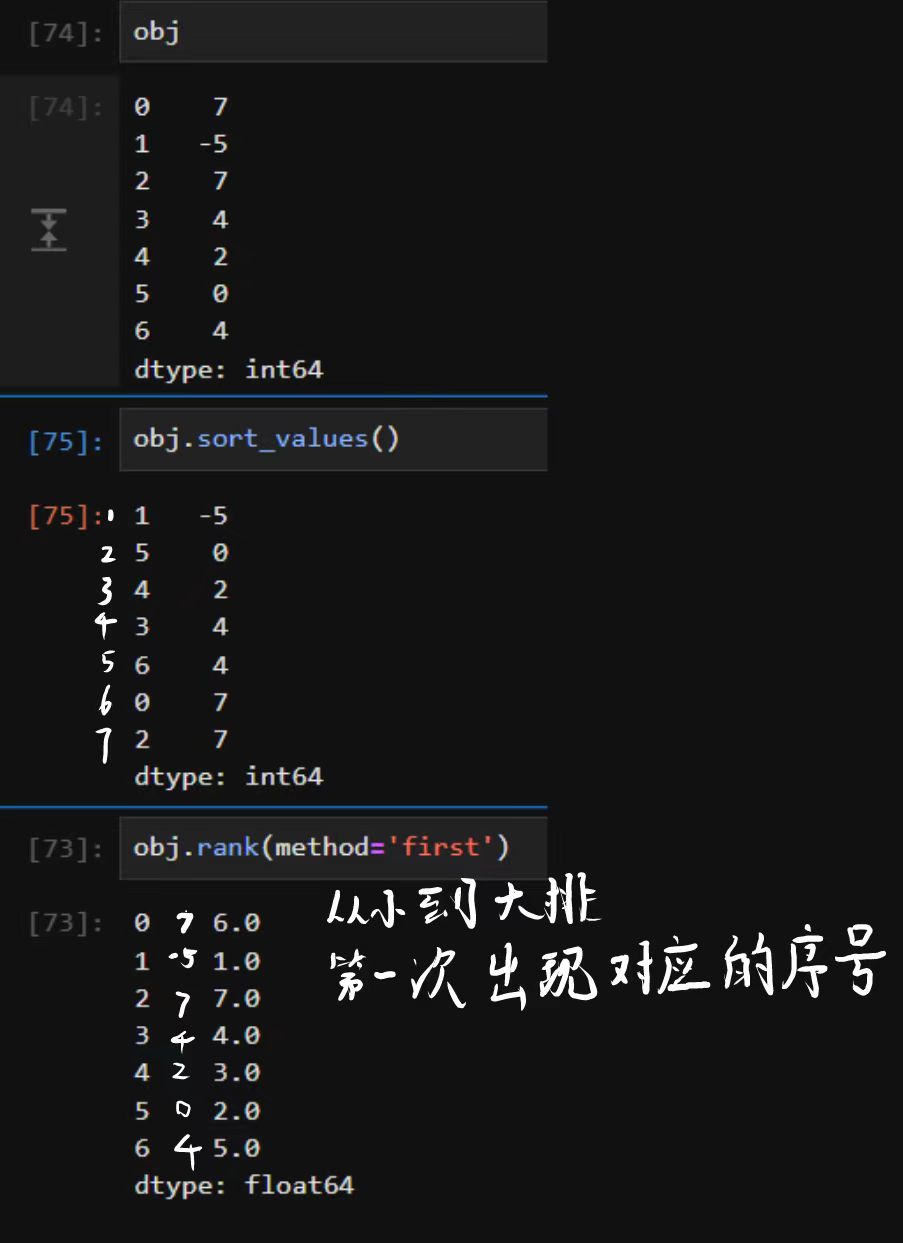
In [41]: obj Out[41]: 04 17 2 -5 33 dtype: int64
In [42]: obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
In [43]: obj Out[43]: Bob 4 Steve 7 Jeff -5 Ryan 3 dtype: int64
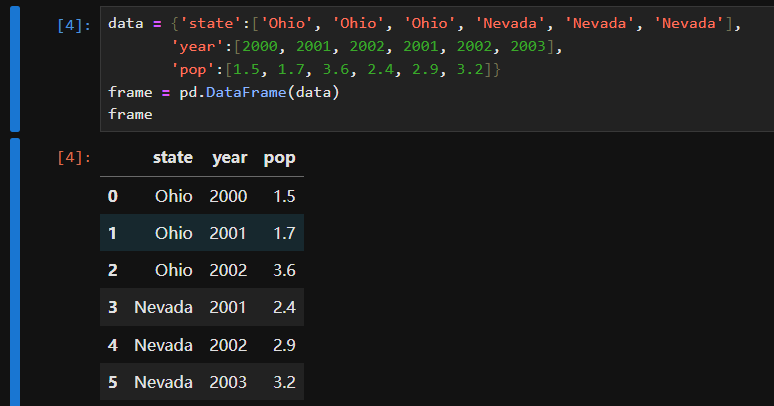
In [53]: frame2.loc['three'] Out[53]: year 2002 state Ohio pop 3.6 Name: three, dtype: object
给缺失值的列赋值
赋同一个值
1 2 3 4 5 6 7 8 9 10 11
In [54]: frame2['debt'] = 16.5
In [55]: frame2 Out[55]: year state pop debt one 2000 Ohio 1.516.5 two 2001 Ohio 1.716.5 three 2002 Ohio 3.616.5 four 2001 Nevada 2.416.5 five 2002 Nevada 2.916.5 six 2003 Nevada 3.216.5
赋不同的值
1 2 3 4 5 6 7 8 9 10 11
In [56]: frame2['debt'] = np.arange(6.)
In [57]: frame2 Out[57]: year state pop debt one 2000 Ohio 1.50.0 two 2001 Ohio 1.71.0 three 2002 Ohio 3.62.0 four 2001 Nevada 2.43.0 five 2002 Nevada 2.94.0 six 2003 Nevada 3.25.0
注:将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。
赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值:
1 2 3 4 5 6 7 8 9 10 11 12 13
In [58]: val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
In [59]: frame2['debt'] = val
In [60]: frame2 Out[60]: year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 -1.2 three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 -1.5 five 2002 Nevada 2.9 -1.7 six 2003 Nevada 3.2 NaN
根据state是否为'Ohio'添加一列名为eastern的列
1 2 3 4 5 6 7 8 9 10 11
In [61]: frame2['eastern'] = frame2.state == 'Ohio'
In [62]: frame2 Out[62]: year state pop debt eastern one 2000 Ohio 1.5 NaN True two 2001 Ohio 1.7 -1.2True three 2002 Ohio 3.6 NaN True four 2001 Nevada 2.4 -1.5False five 2002 Nevada 2.9 -1.7False six 2003 Nevada 3.2 NaN False
注意:不能用frame2.eastern创建新的列。
用del删除列
1 2 3 4
In [63]: del frame2['eastern']
In [64]: frame2.columns Out[64]: Index(['year', 'state', 'pop', 'debt'], dtype='object')
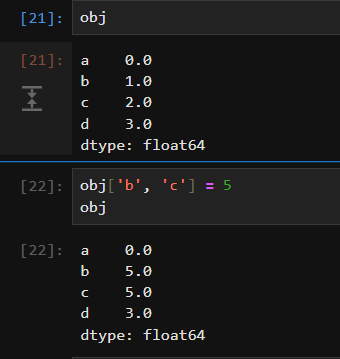
In [117]: obj = pd.Series(np.arange(4.), index=['a', 'b', 'c', 'd'])
In [118]: obj Out[118]: a 0.0 b 1.0 c 2.0 d 3.0 dtype: float64
In [119]: obj['b'] Out[119]: 1.0
In [120]: obj[1] Out[120]: 1.0
In [121]: obj[2:4] Out[121]: c 2.0 d 3.0 dtype: float64
In [122]: obj[['b', 'a', 'd']] Out[122]: b 1.0 a 0.0 d 3.0 dtype: float64
In [123]: obj[[1, 3]] Out[123]: b 1.0 d 3.0 dtype: float64
In [124]: obj[obj < 2] Out[124]: a 0.0 b 1.0 dtype: float64
用切片可以对Series的相应部分进行设置
通过一个值对DataFrame进行索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
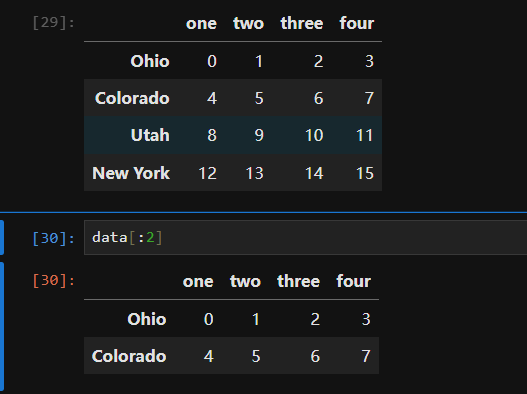
In [128]: data = pd.DataFrame(np.arange(16).reshape((4, 4)), .....: index=['Ohio', 'Colorado', 'Utah', 'New York'], .....: columns=['one', 'two', 'three', 'four'])
In [129]: data Out[129]: one two three four Ohio 0123 Colorado 4567 Utah 891011 New York 12131415
In [130]: data['two'] Out[130]: Ohio 1 Colorado 5 Utah 9 New York 13 Name: two, dtype: int64
通过一个序列对DataFrame索引,主要要套两层[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
In [128]: data = pd.DataFrame(np.arange(16).reshape((4, 4)), .....: index=['Ohio', 'Colorado', 'Utah', 'New York'], .....: columns=['one', 'two', 'three', 'four'])
In [129]: data Out[129]: one two three four Ohio 0123 Colorado 4567 Utah 891011 New York 12131415 In [131]: data[['three', 'one']] Out[131]: three one Ohio 20 Colorado 64 Utah 108 New York 1412
通过切片索引选取行
通过在列基础上条件判断索引
通过对整体条件判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
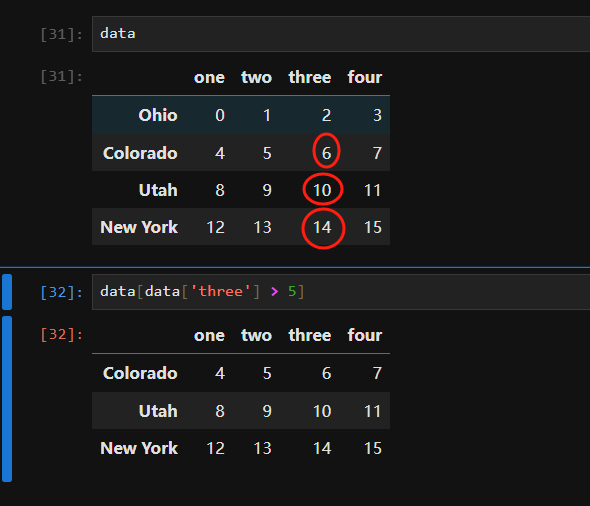
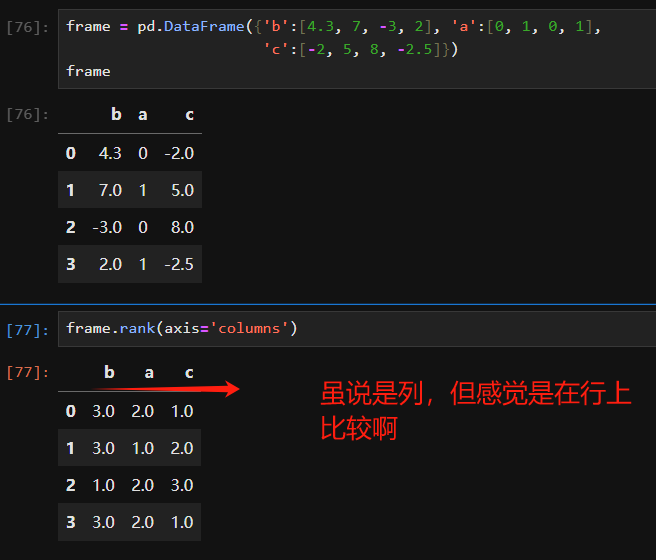
In [134]: data < 5 Out[134]: one two three four Ohio TrueTrueTrueTrue Colorado TrueFalseFalseFalse Utah FalseFalseFalseFalse New York FalseFalseFalseFalse
In [135]: data[data < 5] = 0
In [136]: data Out[136]: one two three four Ohio 0000 Colorado 0567 Utah 891011 New York 12131415
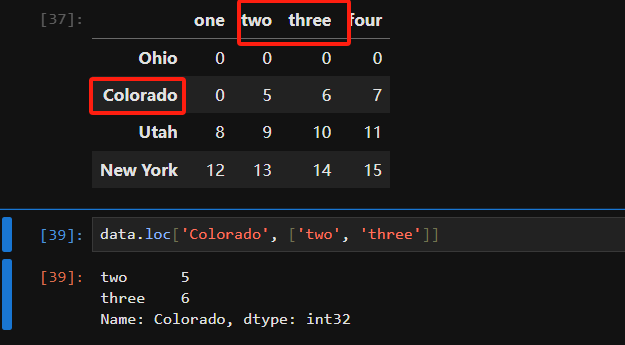
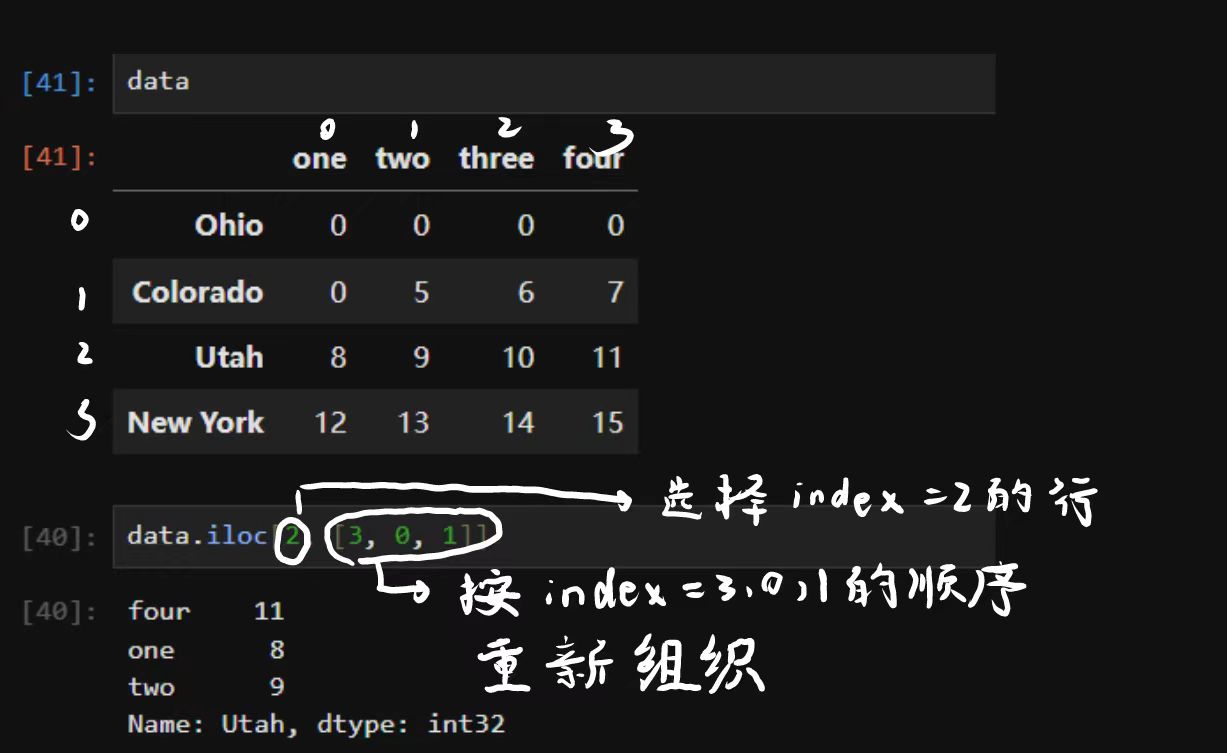
用loc和iloc从DataFrame选择行和列的子集。
使用loc直接选取轴名称
使用iloc通过轴下标选取
切片获取标签
1 2 3 4 5 6 7 8 9 10 11 12
In [141]: data.loc[:'Utah', 'two'] Out[141]: Ohio 0 Colorado 5 Utah 9 Name: two, dtype: int64 In [142]: data.iloc[:, :3][data.three > 5] Out[142]: one two three Colorado 056 Utah 8910 New York 121314
In [157]: df1 Out[157]: b c d Ohio 0.01.02.0 Texas 3.04.05.0 Colorado 6.07.08.0
In [158]: df2 Out[158]: b d e Utah 0.01.02.0 Ohio 3.04.05.0 Texas 6.07.08.0 Oregon 9.010.011.0 In [159]: df1 + df2 Out[159]: b c d e Colorado NaN NaN NaN NaN Ohio 3.0 NaN 6.0 NaN Oregon NaN NaN NaN NaN Texas 9.0 NaN 12.0 NaN Utah NaN NaN NaN NaN
In [165]: df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)), .....: columns=list('abcd'))
In [166]: df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)), .....: columns=list('abcde'))
In [167]: df2.loc[1, 'b'] = np.nan
In [168]: df1 Out[168]: a b c d 00.01.02.03.0 14.05.06.07.0 28.09.010.011.0
In [169]: df2 Out[169]: a b c d e 00.01.02.03.04.0 15.0 NaN 7.08.09.0 210.011.012.013.014.0 315.016.017.018.019.0 In [170]: df1 + df2 Out[170]: a b c d e 00.02.04.06.0 NaN 19.0 NaN 13.015.0 NaN 218.020.022.024.0 NaN 3 NaN NaN NaN NaN NaN In [171]: df1.add(df2, fill_value=0) Out[171]: a b c d e 00.02.04.06.04.0 19.05.013.015.09.0 218.020.022.024.014.0 315.016.017.018.019.0
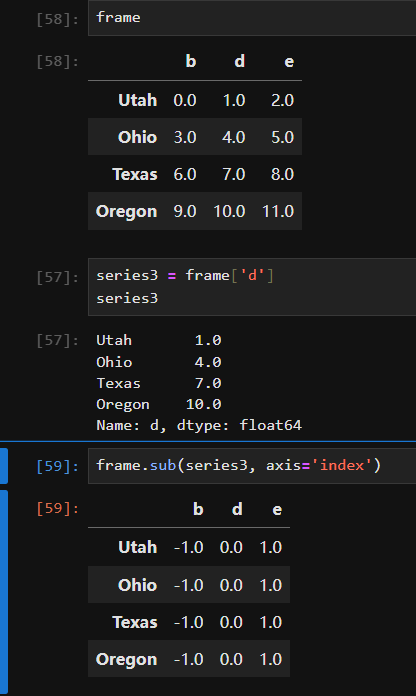
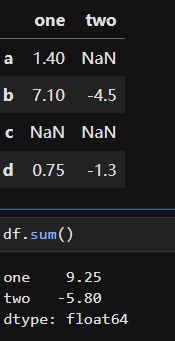
In [181]: frame Out[181]: b d e Utah 0.01.02.0 Ohio 3.04.05.0 Texas 6.07.08.0 Oregon 9.010.011.0
In [182]: series Out[182]: b 0.0 d 1.0 e 2.0 Name: Utah, dtype: float64 In [183]: frame - series Out[183]: b d e Utah 0.00.00.0 Ohio 3.03.03.0 Texas 6.06.06.0 Oregon 9.09.09.0