自动编码器特点
1 跟数据相关程度很高,这意味着自动编码器只能压缩与训练数据相似的数据
2 压缩后数据是有损的
自动编码器的构成
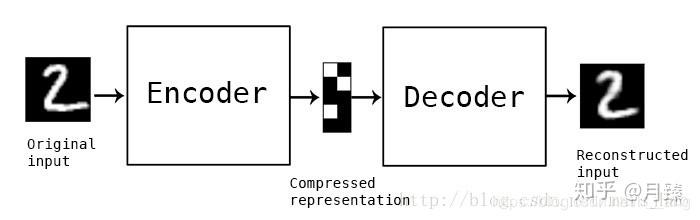
第一个部分是编码器(Encoder),第二个部分是解码器(Decoder),编码器和解码器都可以是任意的模型,通常使用神经网络作为编码器和解码器
自动编码器应用
1 数据去噪
噪声是测量中的随机误差或偏差,包括错误值或者偏离期望的孤立点。简单来说就是对任务或者模型没有帮助甚至有误导作用的数据。
编码器通过学习将潜在空间中的尽可能多的相关信息保留,丢弃不相关部分(噪声)。
解码器学习潜在空间信息重建与输入一致的,这样就达到了去噪。
2 可视化降维
设置合适的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。因为自编码属于无监督学习,所以只需要训练数据就可以得到较好的特征
3 特征提取
自动编码器学习到的特征h,可以作为有监督模型的输入,这样就起到了特征提取器的作用。
自动编码器对深层网络分层训练的过程
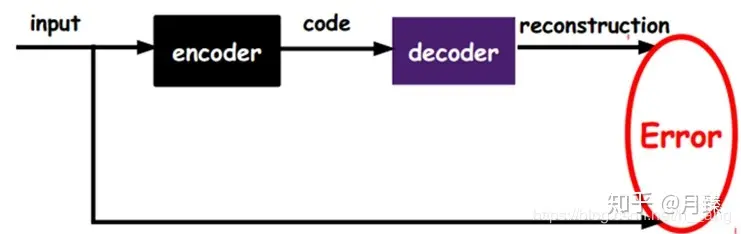
传递到一层,先通过这层的encode编码,再通过decode解码,将解码出来的结果output与原始input比较,相似到某种程度(专业点就是重构误差最小),这时候可以将这一层的output传递作为下一层的input,否则继续调整参数,每一层操作都类似
几种自动编码器基于pytorch的实现
基于全连接层的实现
特点
1 上一层的输出通道等于下一层的输入
2 解码器正好与编码器对称
3 损失函数:均方误差损失函数
nn.MSELoss(),而不是交叉熵损失。这是因为自动编码器的任务是重建输入数据,而不是进行分类。
4 图片保存
1 | if (epoch+1) % 5 == 0: |
to_img(output.cpu().data)
将模型输出转换成图像格式,然后通过 save_image
函数将这个batch的图像拼接保存到一个文件中,文件名包含了该周期的信息。这样,就可以观察到每5个周期训练过程中模型生成的图像重建效果。
4 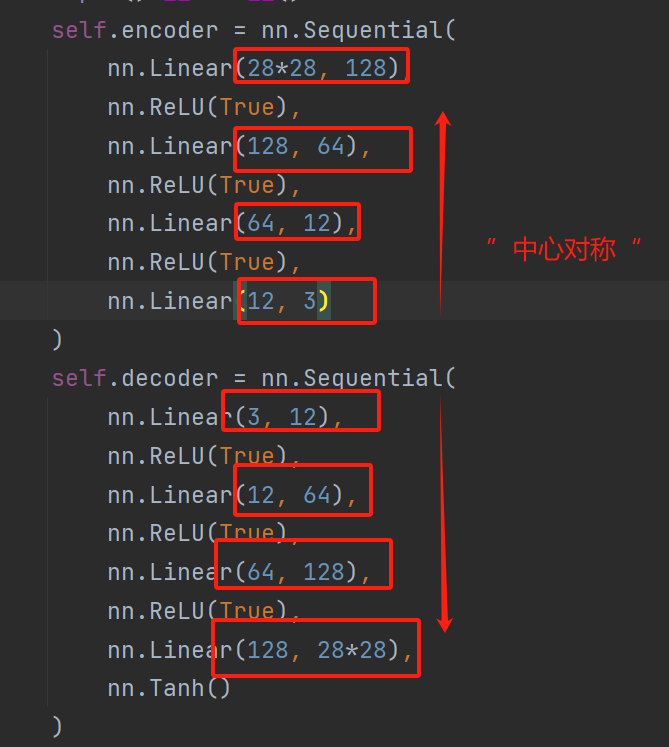
代码
基于卷积神经网络的实现
特点
反卷积
1 卷积神经网络相对于全连接的实现要自由得多,解码器只需要在第一层反卷积输入通道数等于编码器最后一层卷积输出通道数,解码器最后一层反卷积输出通道数等于编码器第一层卷积输入通道数
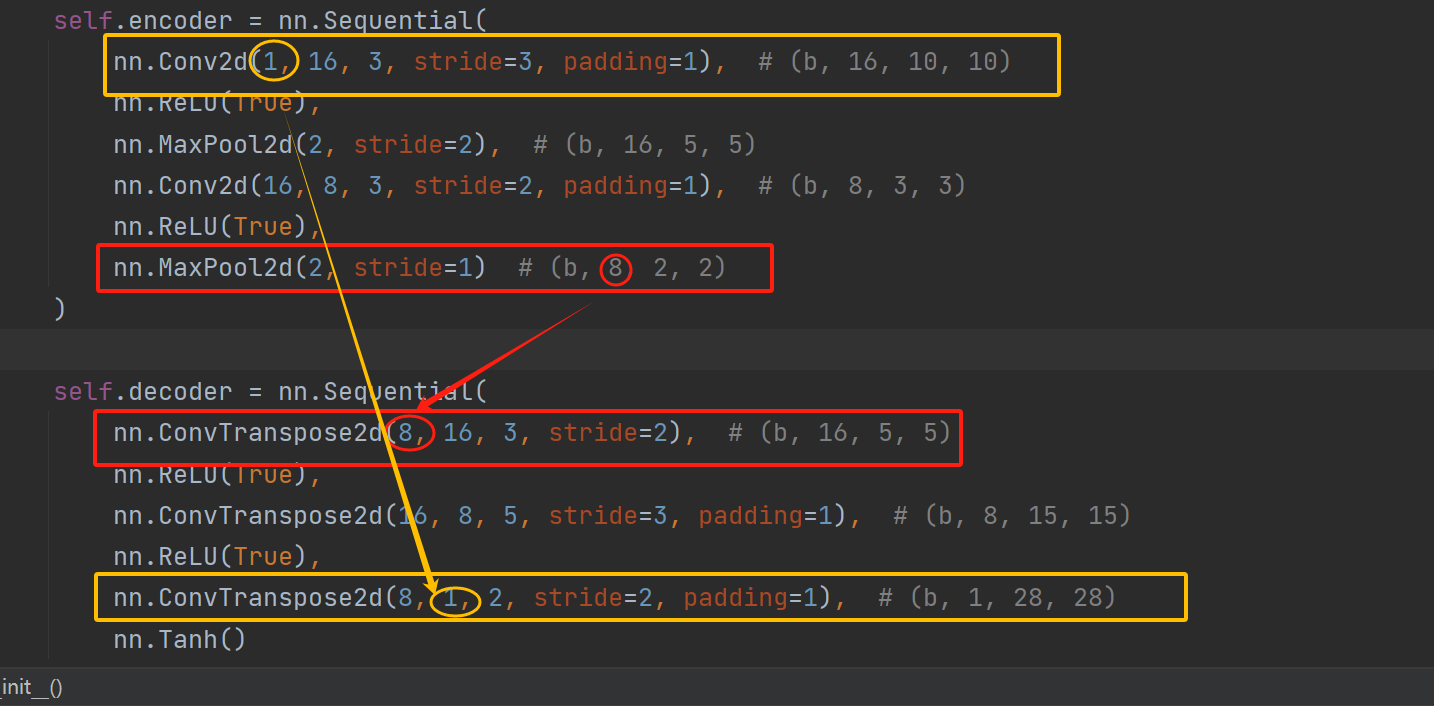
2 计算公式
解码器前面可以随便浪,但最后一层一定要将图片恢复到原来输入的样子,不仅包括通道,还有宽和高
常用公式的简化版本
\(图像输出尺寸 = (图像输入尺寸 - 1) × 步长 - 2 × 填充 + 卷积核大小\)
代码
变分自动编码器
特点
一般的编码器只能“一对一”,给它什么它就会尽可能解码出什么
变分自动编码器通过给它一个标准正态分布的随机隐含向量,通过解码器就能够生成想要的图片,而不需要先给它一张原始图片编码。
在实际情况中,需要在模型的准确率和隐含向量服从标准正态分布之间做一个权衡,所谓模型的准确率就是指解码器生成的图片与原始图片的相似程度。可以让神经网络自己做这个决定,只需要将两者都做一个loss,然后求和作为总的loss,这样网络就能够自己选择如何做才能使这个总的loss下降
另外要衡量两种分布的相似程度,需要引入一个新的概念,KL divergence,这是用来衡量两种分布相似程度的统计量,它越小,表示两种概率分布越接近。
本质上VAE就是在encoder的结果添加了高斯噪声,通过训练要使得decoder对噪声有一定的鲁棒性,这样的话我们生成一张图片就没有必须用一张图片先做编码了,可以想象,我们只需要利用训练好的encoder对一张图片编码得到其分布后,符合这个分布的隐含向量理论上都可以通过decoder得到类似这张图片的图片。
n.MSE()函数,需要声明的是nn.MSE(reduction='sum')求的是每个batchsize上的loss值,最后除以batchsize就可以得到每个输入的loss均值;nn.MSE(reduction='mean')求的是所有元素的均值,而非每个输入的均值,因为每个输入是2828的向量,使用nn.MSE(reduction='mean')计算出来的是nn.MSE(reduction='sum')/(784 batchsize)。所以我们这里用的是nn.MSE(reduction='sum'。)