绪论
Deepfake伪造
图像生成
DCGan
核心原理就是在鉴别器中采用L2损失函数替代原本的对数损失函数,一定程度上提高了GAN 模型稳定性和图像伪造的效果
ProGAN
同时在生成器网络和鉴别器网络中稳定地增加网络层:训练时,以低像素图像为起始数据,通过不断在模型中添加网络层对图像细节进行完善
SinGAN
以在一张图像或者一张包含噪声的图作为输入的情况下,生成新图像
图像篡改
Deepfake
采用两对编码器-解码器网络,但在训练时两个编码器共享参数,分别训练两个解码器。测试时将原脸A输入编码器,再连接B的解码器,解码即可完成将B的脸换为A 的脸
Faceswap-gan
在Faceswap 的基础上引入对抗损失函数和感知损失,并与GAN 结合达到了人脸交换的目的
Face2Face
根据图像的光度一致性原理对原视频和目标视频的表情进行追踪,然后通过目标检索的方法对面部属性进行精准匹配, 最后将数据进行扭曲后完成交换元素的无缝衔接
Deepfake 检测研究
一个端到端的Deepfake 检测系统
引入了强化学习的思想,先用其他数据集在InceptionV3 网络上进行预训练,然后用预训练过的模型对Deepfake 数据集进行训练和测试,该方法很大程度上在提高了模型检测效率和检测效果
此外,基于Xception 网络、注意力机制模块以及Transformer 模型的深度伪造检测方法也可达到较高的准确率
采用多个网络来提取图像不同角度的特征联合检测图像真伪
多流网络检测算法
将人脸分割成多块,分别发送到不同的Resnet18,最后连接一个全连接(Fully Connected layer,FC)层输出检测结果
双流检测方法
使用卷积神经网络学习图像边界特征并结合图像所具有的隐写噪声的特点,综合鉴别图像的真伪性
研究一种预处理方法以提高Deepfake 检测性能。
提取图像像素域中三个颜色通道上的共生矩阵作为模型输入,基于深度CNN 框架进行训练测试
采用离散傅里叶变换获得每张图像的功率谱特征,然后对其求平均得到图像的频谱图,最后使用简单分类器完成伪造图像取证
利用Haar 小波变换对视频中提取的帧做预处理,通过真伪图像的边缘差异进行Deepfake 检测。
基于生物特征
本实验
研究基于自编码器的Deepfake 检测方法
提取了图像在空间域的高频信息图作为模型输入,并且在编码器网络中引入“Squeeze-and-Excitation”网络块,加强模型的特征提取能力,从而提高鉴别真伪图像的准确率。
采用双流网络结构分别提取图像空间域的高频特征和图像频谱图特征,并对提取的特征进行融合,使得模型在能够综合图像空间域和频域的特征做出决策,提高模型的整体检测效果。
通过消融实验证明提取图像高频信息、添加注意力机制和多模特征融合对于Deepfake 检测的有效性
相关理论
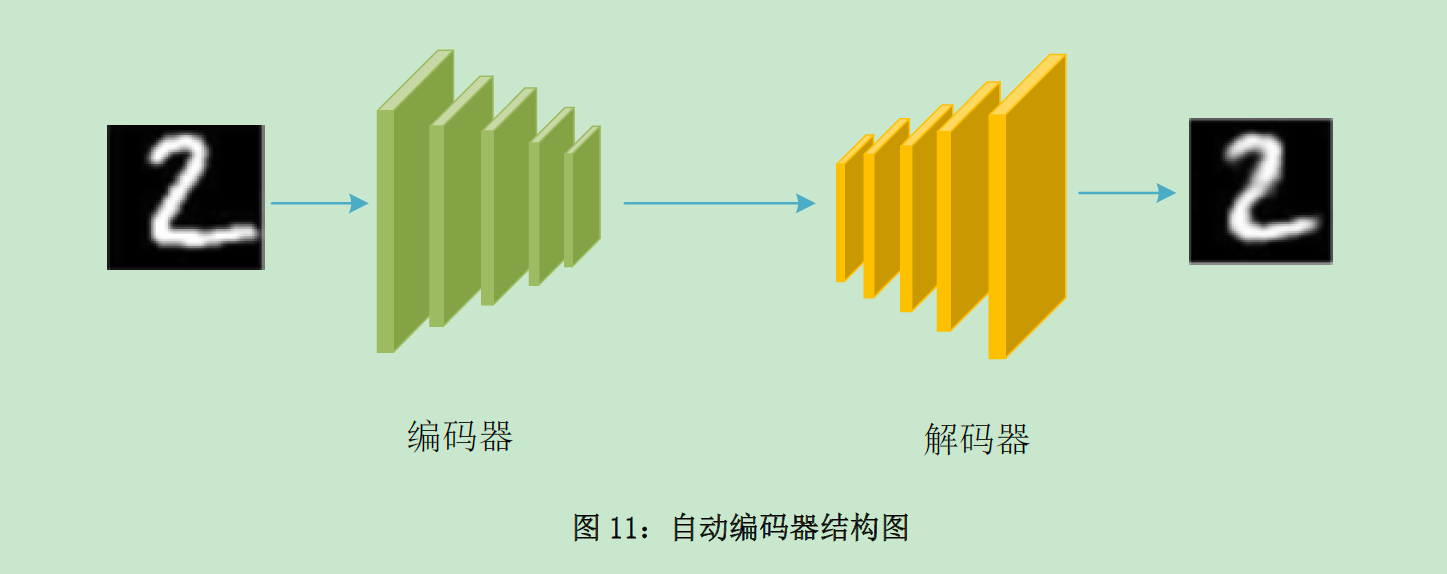
自动编码器
可以通过自编码器,将大量图像数据输入编码器,提取主要特征,然后通过解码器对原图进行恢复
在特征信息越少的情况下,重构信息越准确,那么表示自编码器的性能越好。
注意力机制
多模特征融合
通过融合图像的全局特征(颜色直方图)和局部特征(Bag-OfFeature 模型)的表示图像,然后,将融合后的特征作为分类器的输入数据,使得 识别率得到显著提高。
早期融合方法只需要对单一模型进行训练
晚期的融合方法是对各模块单独训练首先根据输入的模态生成与之相对应的模型,然后设计一种融合机制对不同模型得到的结果进行集成,常用的融合机制有投票选举法,平均方法,基于信道噪声和信号方差的加权方法以及设计并训练一个融合模型等。
Deepfake 算法
一种是基于生成对抗网络GAN
由一个生成器网络(Generator,G)和一个鉴别器网络 (Discrimistor,D)组成
首先,生成器可将潜在空间中的噪声生成图像,然后将其和真实图像混合输入鉴别器进行分类
鉴别器网络本质是一个二分类模型,主要作用就是鉴别真实图像和伪造图像
训练时,生成器和判别器迭代优化,不断更新模型参数,直到达到纳什平衡
一种是基于自动编码器网络
Deepfake 核心就是一个经过特殊训练的自编码器,用监督学习训练一个神经网络提取人脸的表情特征,然后通过训练后的神经网络还原成其他人的脸
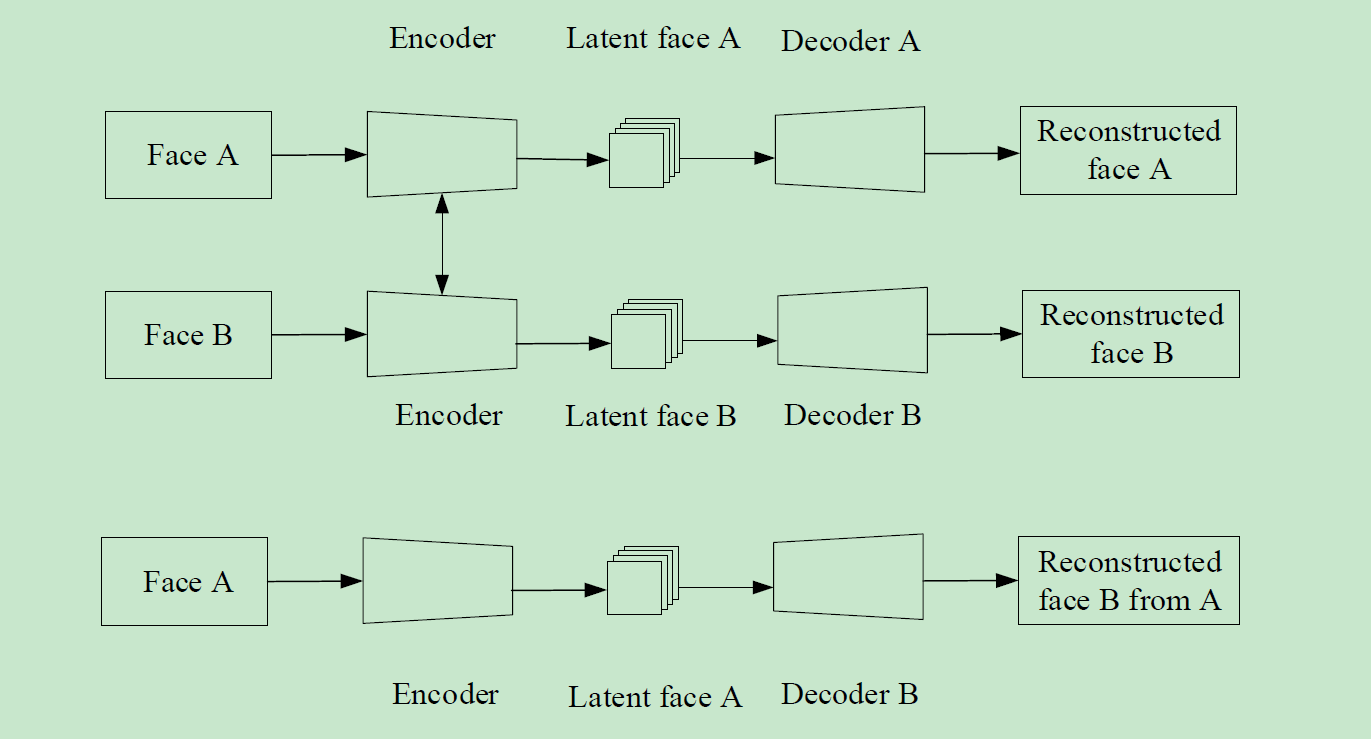
“如上图,在训练时,需要两组编码器-解码器网络,两个编码器网络共享一个编码器权重,而分别对应不同的解码器,这样编码器能 同时对A 和B 两人的共有面部特征进行提取(主要为表情特征),而解码器能对其进行重构,恢复各自脸部图片。”
大白话:公用一个编码器,对应不同解码器
在图像生成时,如果需要将图片中A 的脸替换为B 的脸,可将数据集A 作为输入,得到表情特征,然后输入到解码器B 中 进行解码,即可得到具有A 表情的B 人脸。
基于自编码器的深度伪造图像检测
主要思路
首先提取图像高频信息
紧接着通过自编码器网络提取图像深层特征,并且在编码器网络中引入“Squeeze-and-Excitation”网络块以提取更多有效特征;
最后采用三层全连接网络做分类。
补充
什么是图像的高频信息?
图像的高频信息就是图像边缘变化明显的地方,图像的低频信息就是图像的内部变化缓慢的地方
用高斯滤波计算出低频信息后,用原图-低频就得到高频,就向下图那个像拓印的图
计算低频信息的方法

模型框架
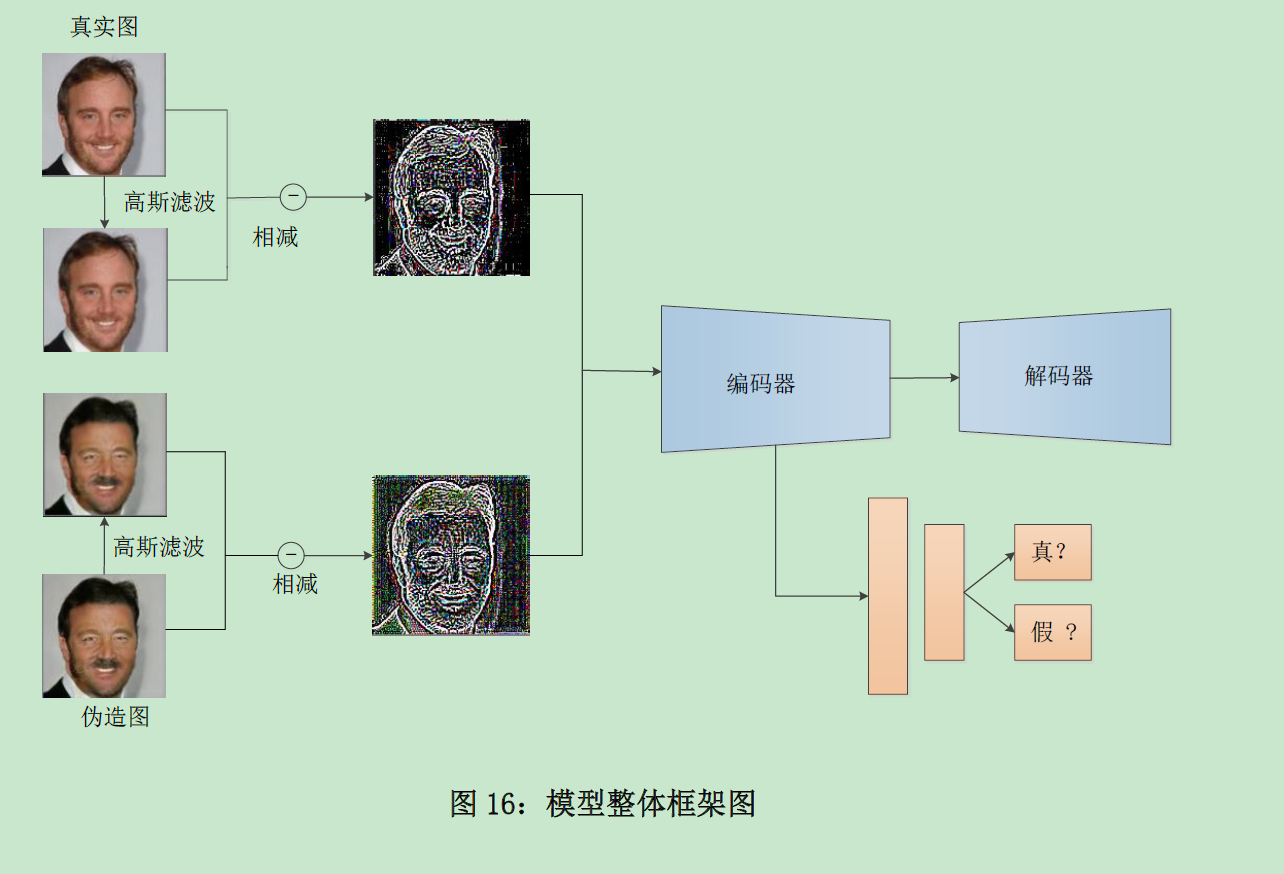
预处理阶段
高斯滤波是一种线性的平滑滤波,在计算过程中,卷积核的大小是固定的,以计算像素位置为原点,周围的点用正态分布函数分配对应权重,最后通过计算加权平均值即可得到最终值
所以在预处理过程中,先用高斯滤波获取输入图像低频信息图,然后将原图像与低频信息图做差以保留高频信息
自编码器网络
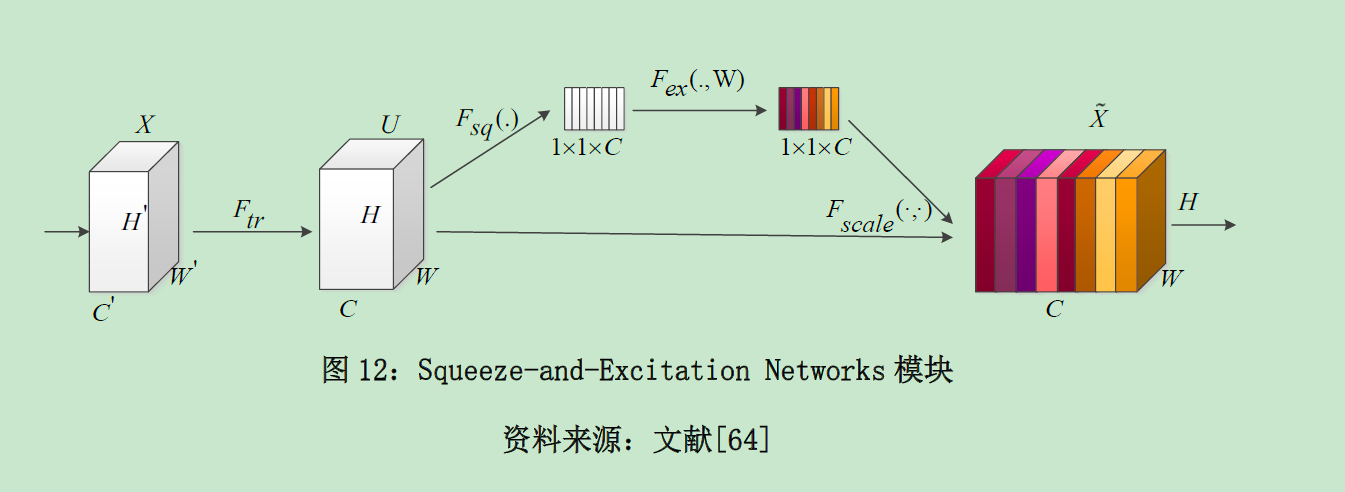
本文编码器中引用了Squeeze-and-Excitation(SE-Block),其核心思想是:网络根据损失函 数学习获得通道特征的权重值,根据其对任务的有效性分配一定的权重
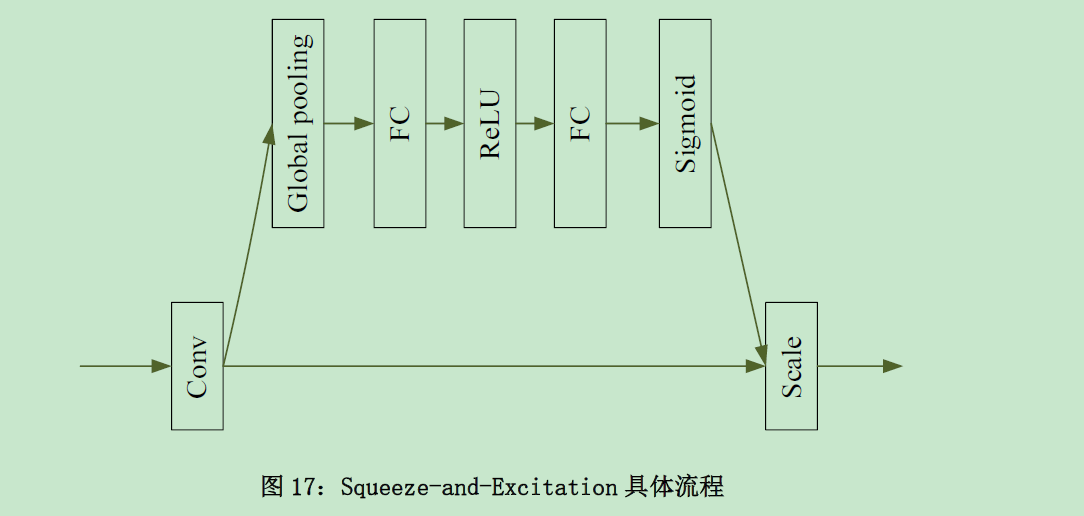
在特征提取阶段,采用一个自编码器网络对高频信息图进行特征提取,同时,在编码器中添加“Squeeze-and-Excitation”模块,该模块 能够根据不同通道特征对检测任务的重要性进行合理提取,保证特征提取的有效性;
在图像分类阶段,本文分类器由三个全连接层组成。在检测过程中,由编码器直接对图像高频信息图编码后输入全连接层,即可输出图像的真伪
基于多模特征融合的深度伪造图像检测
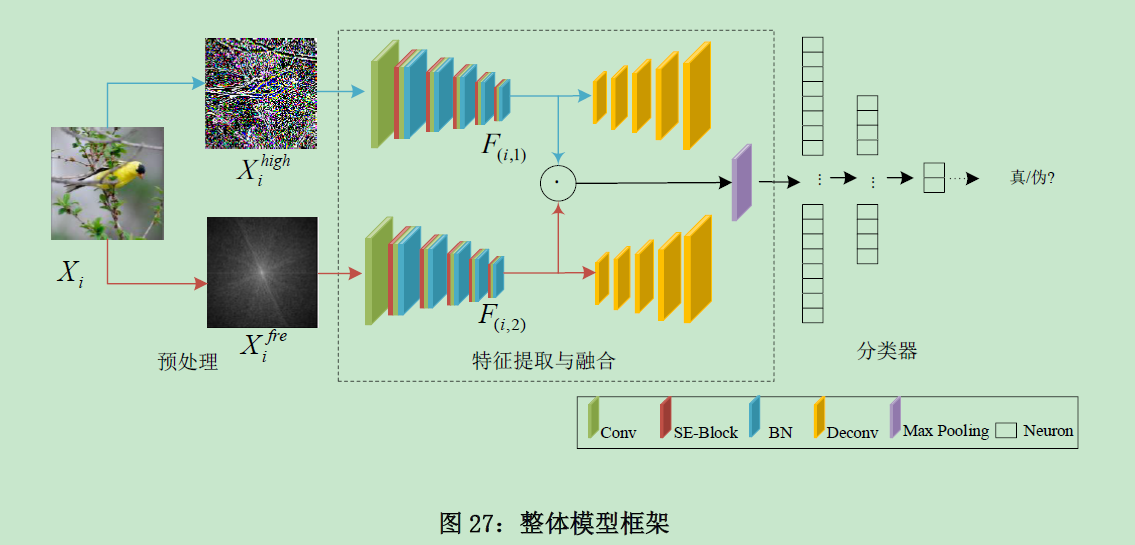
首先对图像进行预处理,保留图像高频信息,并且对通过傅里叶变换获取图像的频谱图;接着通过双流网络来提取预处理图像的特征并进行融合;最后将融合后的特征图作为分类器(三层全连接)的输入进行分类。
模型框架
采用双流自动编码器网络结构作为主干网络。
通过融合图像在空间域和频域的特征进行Deepfake 检测预处理阶段,分别采用高斯滤波和傅里叶变换提取图像的高频信息图和图像的频谱图
在特征提取和融合阶段,首先,通过两个编码器分别提取图像在空间域和频域的特征,然后 对编码器提取的特征图进行融合,最后添加最大池化层对融合特征降采样
在图像分类阶段,采用三层全连接网络结构。
预处理
与在空间域中提取的特征图相比,图像的某些特征在频域中更为突出,特别是图像的重复性和频率特征可以通过傅里叶变换来分析
在图像空间域一般很难检测出图像的全局纹理信息,但在图像的频域内检测相对容易,而Deepfake 图像往往在纹理上存在一定的缺陷

图像傅里叶变换过程
1.将原图转换为灰度图; 2.进行傅里叶变换; 3.将图像变换的源点移动到频域矩阵中心; 4.对傅里叶变换结果进行对数变换; 5.对中心化后的结果进行对数变换。
图像傅里叶变换后,其高频信息聚集在中间,低频信息分布在四角。
为了把能量集中起来以方便滤波器的使用,利用二维傅里叶变换的平移性质对频谱进行中心化。所以要对频谱中心化后的效果,就是低频在中间,高频在四周,
最后将中心化后的图像作为自动编码器网络的输入
特征提取与融合
采用双流网络结构进行特征提取
首先,预处理得到的高频图和频谱图作为模型输入;
其次,一个自编码器用来提取像素域高频图特征,
另一个自编码器用来提取频谱图特征,并且对提取的空间域和频域特征进行融合;最后,融合特征经过一层最大池化层后输入分类器。