专有名词解释
用于对抗过拟合的技术称为正则化
训练误差(training error)
模型在训练数据集上计算得到的误差
泛化误差(generalization error)
模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望。实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差, 该测试集由随机选取的、未曾在训练集中出现的数据样本构成
解决方法
K折交叉验证
原始训练数据被分成k个不重叠的子集。 然后执行k次模型训练和验证,每次在k−1个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。 最后,通过对k次实验的结果取平均来估计训练和验证误差。
应用最广泛的解决过拟合的正则化方法:权重衰减
通常也被称为L2正则化
L2正则化线性模型构成经典的岭回归(ridge regression)算法
使用L2范数的一个原因是它对权重向量的大分量施加了巨大的惩罚。 这使得我们的学习算法偏向于在大量特征上均匀分布权重的模型
暂退法(Dropout)
定义
在前向传播过程中,计算每一内部层的同时注入噪声
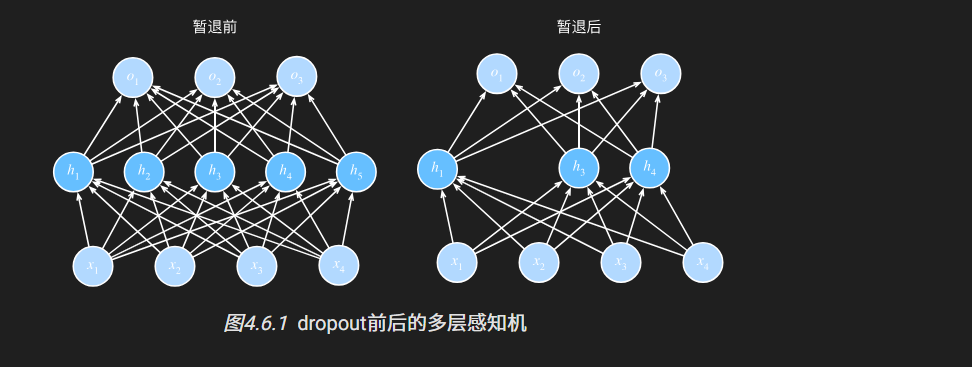
应用
可以将暂退法应用于每个隐藏层的输出(在激活函数之后)), 并且可以为每一层分别设置暂退概率
常见的技巧是在靠近输入层的地方设置较低的暂退概率
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层,
将暂退概率作为唯一的参数传递给它的构造函数。
在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。
在测试时,Dropout层仅传递数据。
1 | net = nn.Sequential(nn.Flatten(), |
批量规范化
基本原理
在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。 接下来,我们应用比例系数和比例偏移。
批量规范化层
全连接层
将批量规范化层置于全连接层中的仿射变换和激活函数之间
卷积层
在卷积层之后和非线性激活函数之前应用批量规范化
代码
1 | net = nn.Sequential( |