三种与类型有关的运算id, type, isinstance
id(变量名) 获取变量内存地址
type(变量名)获取变量类型
isinstance(变量名,预测的数据类型)获取变量类型
举例
1 | string = "hello, world" |


type(变量名)获取变量的数据类型,它不会认为子类和父类是相同的数据类型 isinstance(变量名,预测的数据类型)预测变量是什么类型,它会认为子类和父类是相同
Number常用的模块
math(import math)
求绝对值
1 | print(math.fabs(-5)) |
向上取整 math.ceil(3.1)
向下取整 math.floor(3.9)
求平方 math.pow(2, 3)
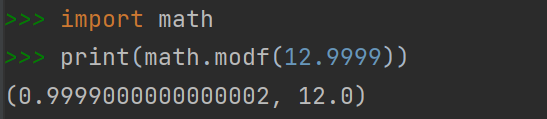
同时求整数部分和小数部分 math.modf(12.999)
1 | print(math.modf(12.9999)) |
求正弦 math.sin(3)
random(import random)
生成0 ~1 之间随机数 random.random()
生成指定范围的随机数(左闭右开) random.randrange(1, 100)
生成指定范围的一个整数(左闭右闭) random.randint(0, 10)
返回随机一个元素 random.choice()
1 | lis = ["小明", "小红", "小芳"] |
随机打乱序列里面元素
1 | li = ['一个水杯','一台电脑','一支笔','一副眼镜','一件风衣'] |
随机获取部分元素
1 | str = '0123456789abcdefghijklmnopqrstuvwxyz' |
字符串
切片(语法格式:[开始值:结束值:步长])
1 | # 从最后一个开始从后两个两个往前 |

查
find:检测子字符串是否包含在母字符串中,如果是返回开始元素的索引值,否则返回-1
index:跟find方法一样,只不过如果str不在myStr中,直接报错
count:返回子字符串在start和end的母字符串中出现的次数
isalpha:判断一个字符串是不是全是字母
isdigit:判断一个字符串是不是全是数字
改
replace:把母字符串中str1(旧元素)替换为str2(新元素),如果指定了count,则替换不超过count次
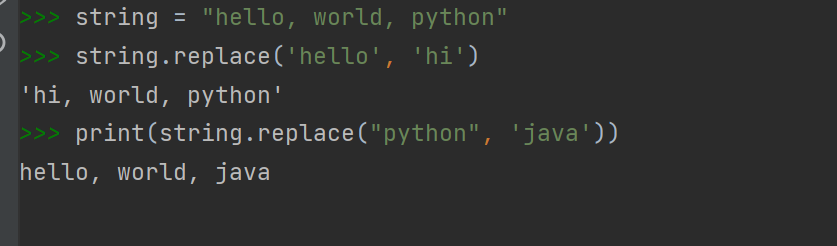
但是string并没有修改

split: 分割,以str为分隔符切片母字符串, 返回的是列表(分割后的每一个元素作为列表中的元素(String)
1 | string = "hello, world, python" |

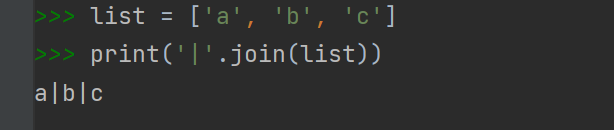
join:用指定字符将列表中元素连接成一个字符串,其中指定字符串加在列表中元素后面
获得字母的ASCII码
ord()用来返回一个字母的ASCII码
chr()相当于逆运算
空格
.lstrip()删除字符串左空格
.rstrip()删除字符串右空格
.strip()删除两端空格
对齐
.ljust(width):左对齐并用空格填充到长度为width
.rjust(width):右对齐并用空格填充到长度为width
.center(width):居中并用空格填充到长度为width
列表
增
append(在末尾插入)
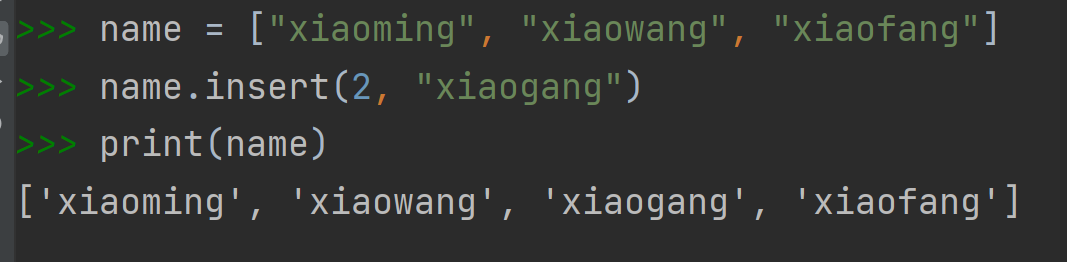
insert(在指定位置插入,这个指定位置是插入后这个元素在新列表中的位置)
删
del(根据下标删除)
pop(删除最后一个元素)
remove根据元素的值删除
1 | international = ['中国','韩国','日本','美国'] |
查
in(判断一个元素在不在列表中)
count(计算一个元素在列表中个数)
index(得到列表中一个元素下标)
改:直接通过下标修改
求一个列表中最大值和最小值:max(list)和min(list)
exercise1
1 | 练习: |
Answer
1 | import random |

元组
字典
创建
直接用{}创建空字典
1 | dic = {} |
查找
通过键查询值:直接将键作为“下标”
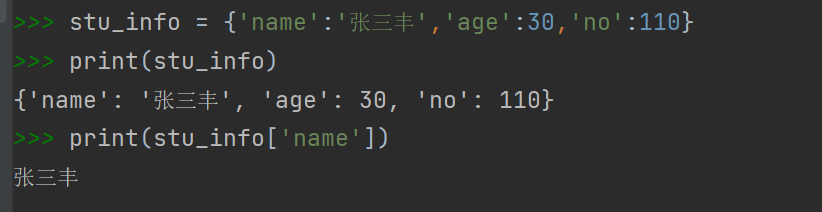
get函数
不确定字典中是否存在某一个键而又想获取它的值,可以使用get(),设置默认值,如果不存在就返回默认值
1 | stu_info = {'name':'张三丰','age':30,'no':110} |

修改
修改元素的值:直接通过查找到的键来修改
1 | # 字典变量名[对应键名] = 新的值 |
添加元素:变量名["键"] = 数据(如果对应的键不存在会自动创建)
1 | stu_info['mobile'] = 13248301214 |
删除元素
删除指定键的元素或整个字典:del
1 | del dic['age'] |
清空整个字典
1 | dic.clear() # 字典内容被清空,字典依然存在 |
遍历
获取字典中键值对的数量:len
1 | len(dic) |
.keys():获取字典中由键组成的列表
1 | allKeys = dic.keys() |
.values():获取字典中由值组成的列表
1 | allValues = dic.values() |
items():返回一个包含所有(键 值)元祖的列表

1 | for key, value in dic.items(): |
集合
创建
set( )函数创建,( )里面可以是字典,列表,元组
大括号创建
集合运算
交 &
并 |
差 -
生成器
创建
列表推导式、
语法:
1 | new_list = [expression for item in iterable if condition] |
expression: 定义列表元素的表达式。item: 迭代变量,表示来自 iterable 的当前元素。iterable: 可迭代对象,例如列表、元组、字符串等。condition(可选): 过滤条件,用于筛选元素。
expression中的变量和item中一致i,expression表示的是最终的返回值
举例
1 | list = [x * x for x in range(10)] |

生成器
1 | generator = (x*2 for x in range(5)) |

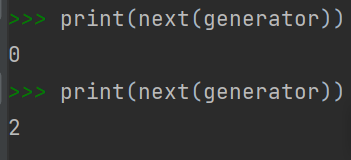
生成器每次返回的是一个算法,每使用一次next函数就可以获取一个元素值, 直到最后一个元素值,
也可以直接用for
1 | for item in generator(): |
yield
举例:构造斐波那契数列
1 | def febo(n): |
yield关键字类似于return关键字,每次迭代遇到yield返回后面的一个元素, 下次再迭代时候,从上一次yield结束位置后面继续执行
迭代器
迭代对象
一类:str list tuple dict set 二类:生成器
这些可以直接作用与for循环的对象的统称 ----》迭代对象 : Iterable
迭代器
可以被next()函数调用并且不断的返回下一个值的对象----》迭代器 Iterator